1、摘要
Transformer对于序列建模是非常强大的。几乎所有最先进的语言模型和预先训练的语言模型都基于 Transformer 体系结构。然而,它仅仅使用标记位置索引区分顺序标记。论文中作者提出一个假设:更好的上下文表示是不是可以从Transformer中产生更丰富的位置信息?为了验证这一点,作者提出了一种分段感知(Segatron)Transformer,将原来的Token位置编码替换为对应段落、句子和Token的联合位置编码。本文首先在 Transformer-XL 中引入了Segatron-aware机制,发现的Segatron-aware方法可以进一步改进 Transformer-XL base模型和large模型,在 WikiText-103数据集上实现17.1的ppl。之后,作者又在Bert中加入 Segatron-aware机制(SegaBERT)。实验结果表明, SegaBERT 在各种 NLP 任务中的表现均优于经过原始的BERT,并且在 zero-shot 句子表征学习中优于 RoBERTa。
2、拟解决问题
在Transformer结构中,引入段落,句子,Token的位置信息,丰富模型的位置编码。,改善网络的Attention。
3、模型训练
1)Segatron-XL
Segatron-XL是在Transformer-XL中引入Segatron-aware机制的一个模型。首先回顾下Transformer-XL的位置编码公式:
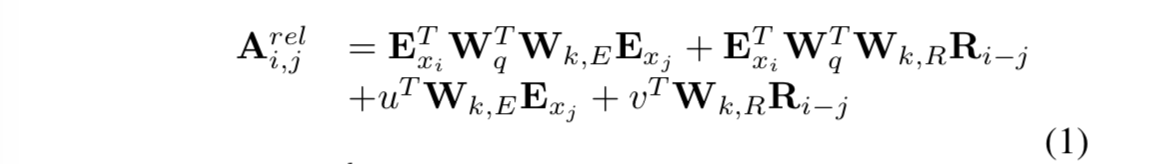 其中:
其中:
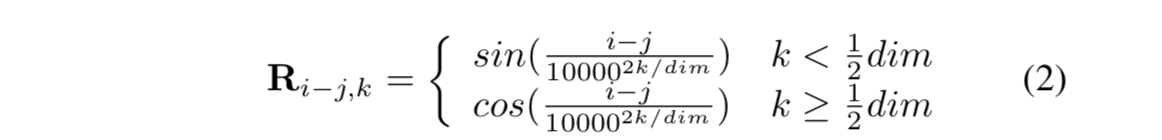 Segatron-XL改进:
Segatron-XL改进:
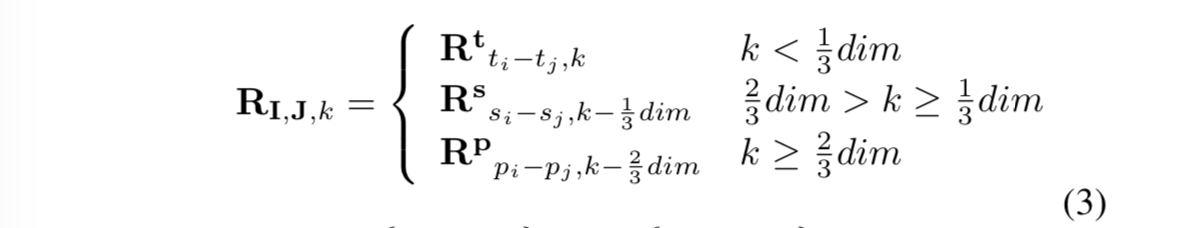 什么意思呢?其实就是说,本来相对位置向量有384维,Transformer-XL每个位置的向量由公式(2)得到384维向量。但是改进之后呢,1/3的维度即128维是t(Token)的位置向量,即将0 ~ tmaxnums代入公式(2),1/3的维度是s(sentence)的位置向量,即0 ~ smaxnums代入公式(2),1/3的维度是p(paragraph)的位置向量,即0 ~ p_maxnums代入公式(2)。这样3部分组成了这个。注意,以上用的公式(2)的dim是预先设定的每个部分的最大值。比如你模型预设输入的最大段落数为20,每个段落最大的句子数为50,每个句子最大的Token数为100,那么上述的dim分别为20, 50, 100。
什么意思呢?其实就是说,本来相对位置向量有384维,Transformer-XL每个位置的向量由公式(2)得到384维向量。但是改进之后呢,1/3的维度即128维是t(Token)的位置向量,即将0 ~ tmaxnums代入公式(2),1/3的维度是s(sentence)的位置向量,即0 ~ smaxnums代入公式(2),1/3的维度是p(paragraph)的位置向量,即0 ~ p_maxnums代入公式(2)。这样3部分组成了这个。注意,以上用的公式(2)的dim是预先设定的每个部分的最大值。比如你模型预设输入的最大段落数为20,每个段落最大的句子数为50,每个句子最大的Token数为100,那么上述的dim分别为20, 50, 100。
位置结构图
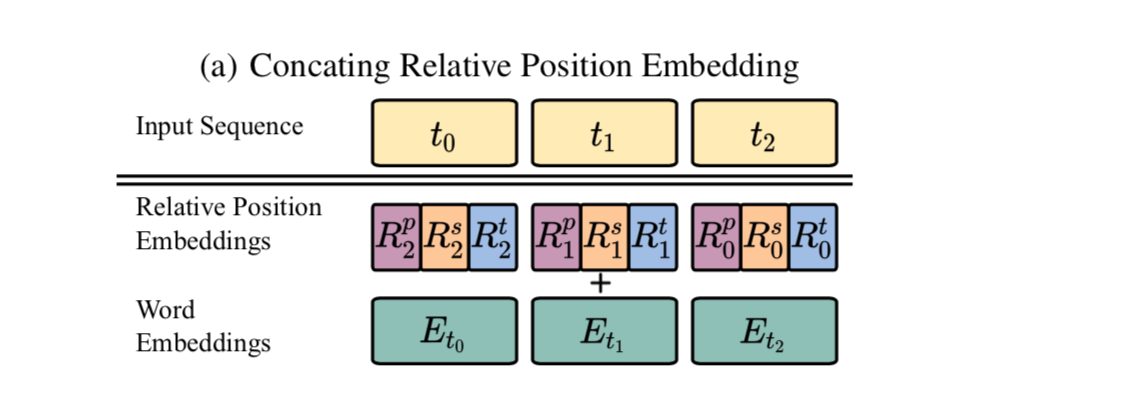 SegaBERT:
SegaBERT:
BERT原始的位置向量Pposition:
Pposition = Ptoken
BERT的最大Token长度为512,那么位置向量就是从0 ~ 511的索引生成的向量。
改进:
Pposition = Ptoken + Psent + Ppara
Ptoken ,Psent , Ppara分别代表Token,句子,段落的索引生成的向量。
比如:
段落:
Language modeling (LM) is a traditional sequence modeling task which requires learning long-distance dependencies for next token prediction based on the previous context.
Recently, large neural LMs trained on a massive amount of text data have shown great potential for representation learning and transfer learning. achieved state-of-the-art results in various natural language processing tasks.
那么,段落索引为:0,1;第一段句子索引分别为:0,第二段句子索引为:0,1;Token的索引为: 0,1,2,3,
.......54。
训练细节
1、去掉了NSP的任务,因为输入的不止2个句子;
2、最大的段落数50, 最大的句子数100, 最大的Token数256;但是最大的句子输入长度为512。意思是,虽然最大的Token索引是256,但是可以超过256;
3、如果索引超过了最大预设长度。则多出来的词的位置索引用最大预测长度索引。如:254,255,255...。
4、输入形式:[CLS] p0s0 [SEP] p0s1... [SEP] p0sn [SEP] p1s0[SEP] p1s1 ...[SEP] pns0 [SEP] pns1... [SEP] pnsn [SEP] 。即段落和句子的分隔符用的是一样的。
5、每篇文章的第一句都是随机从文章中选出;剩余的部分有序拼接到后面。
6、学习率1e-4,adam优化器,β=(0.9, 0.999)。
4、结果
语言模型对比 从下图可以看到,Segatron-XL相比Transformer-XL,效果有很大的提升,ppl降低了1.2。效果和Compressive Transformer相当,但是Compressive Transformer采用的是1024的memory长度。可见,加入新的位置编码向量之后,是很有效的。
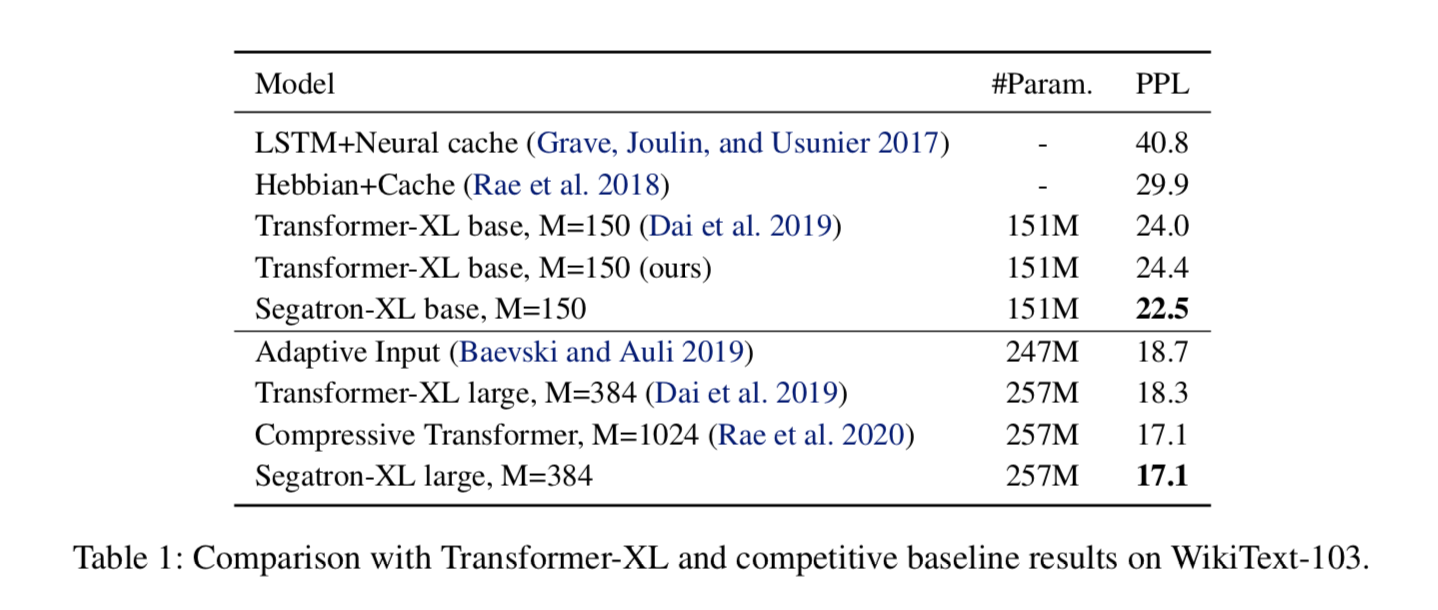
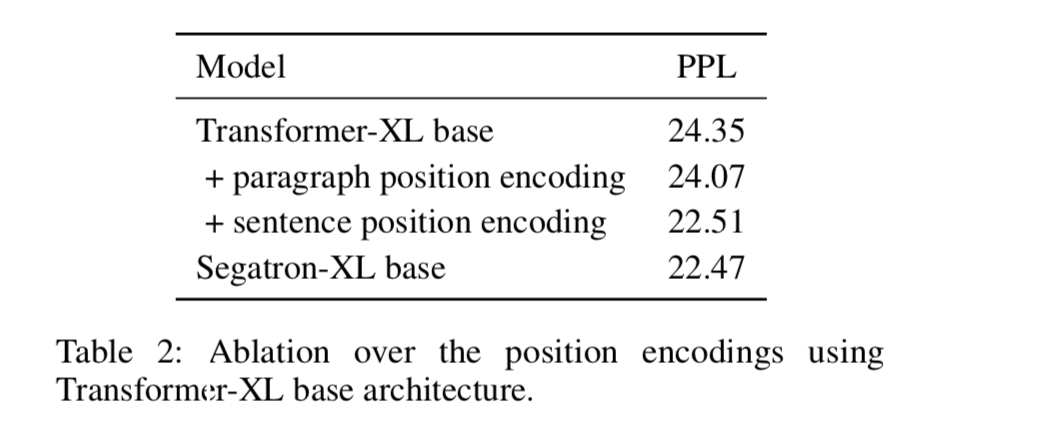
消融实验 论文作者之后做了下消融实验,主要对比了段落索引和句子索引的重要性。从下表可以看出,添加段落索引之后ppl为24.07降低了0.28个ppl,而添加了句子索引之后,ppl下降了1.8个ppl。说明,句子的索引是很关键的,比段落索引重要的多。
Finetune
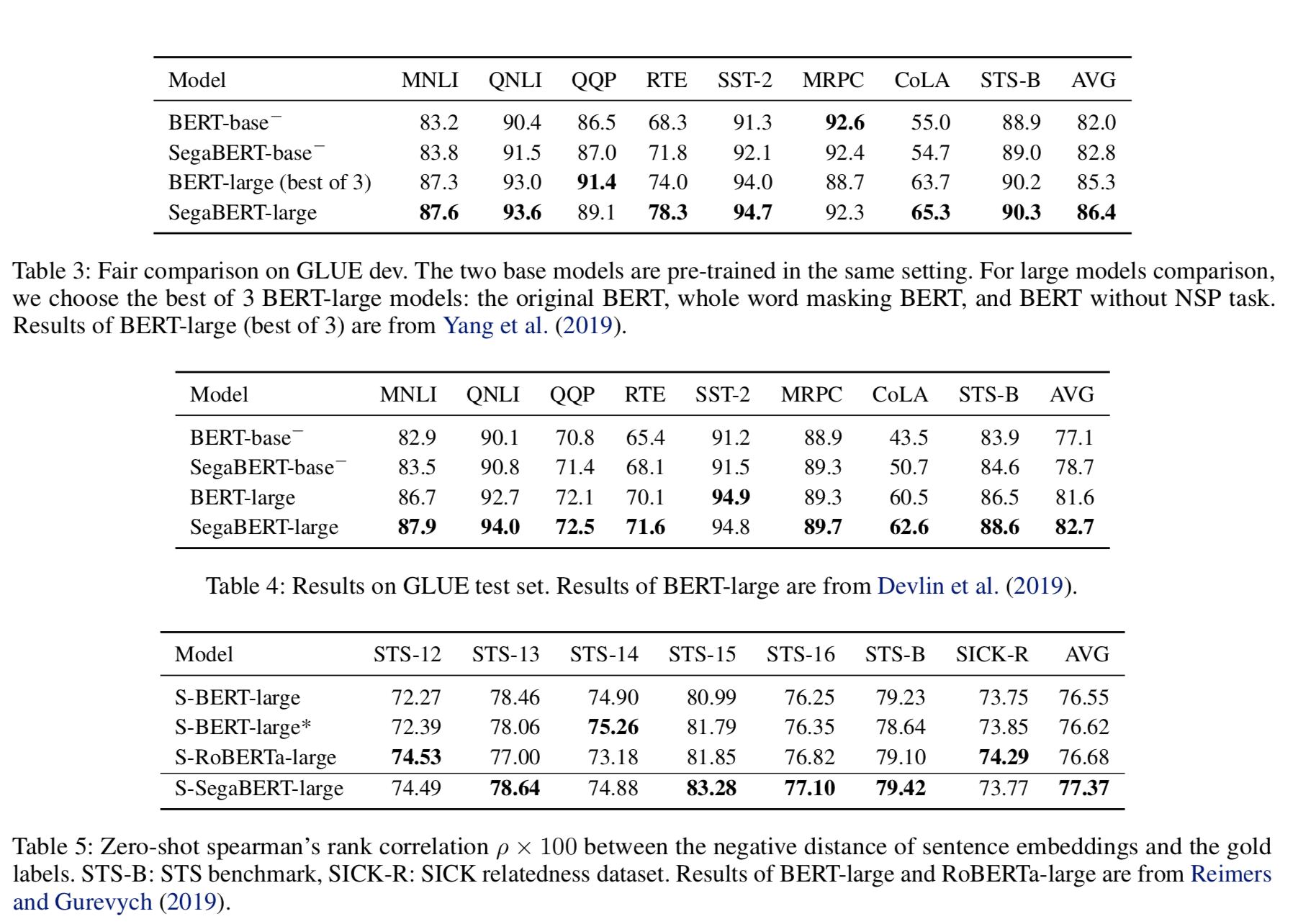 “−”表示作者自己实现的模型;没加“−”表示别人论文中的结果。
从上述表中,可以看到,在GLUE任务上,结果都有一定的提升。
“−”表示作者自己实现的模型;没加“−”表示别人论文中的结果。
从上述表中,可以看到,在GLUE任务上,结果都有一定的提升。注意力可视化
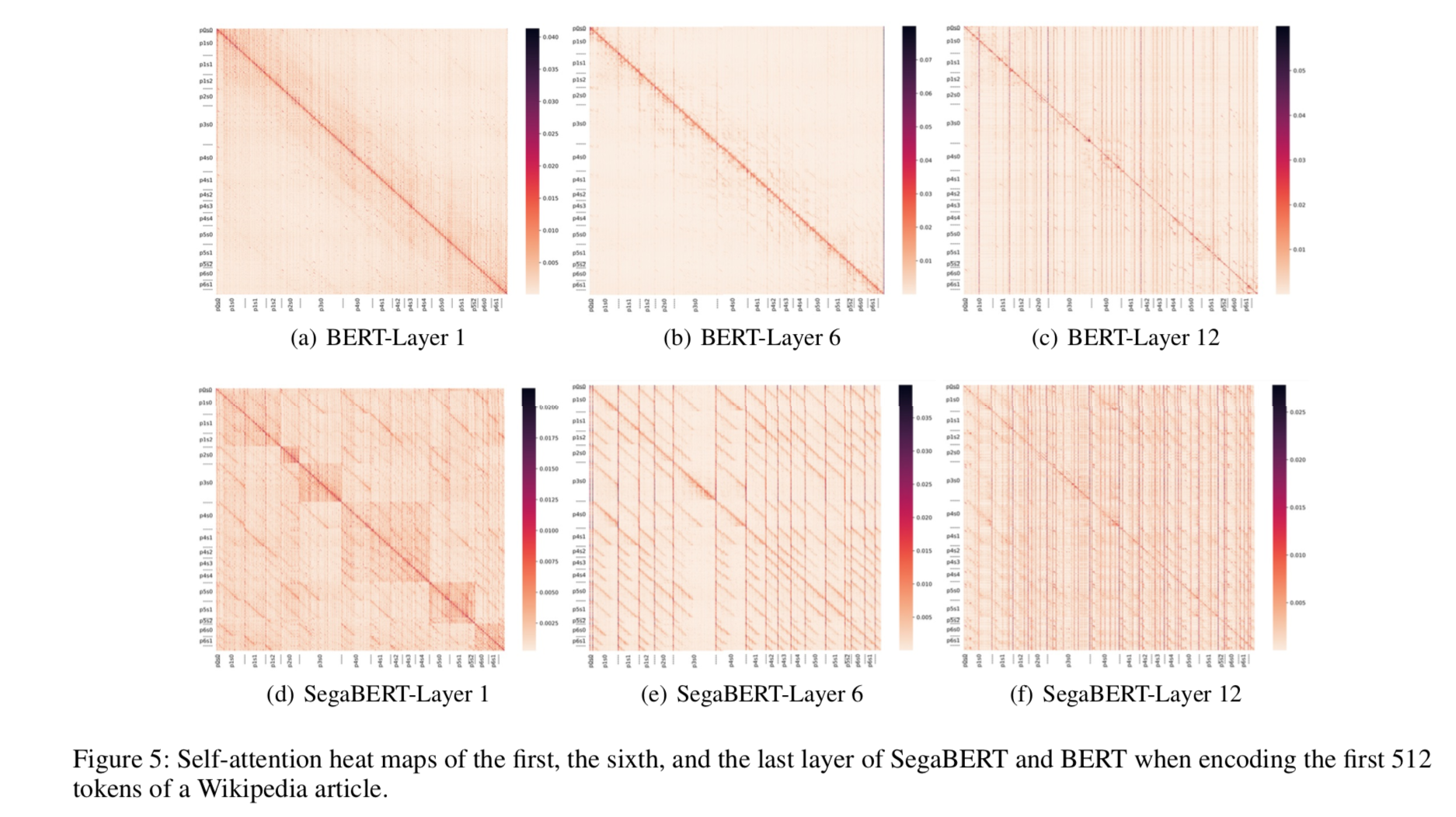
上图5显示了不同注意力集中程度的平均分数。通过比较图5(d)和图5(a) ,发现 SegaBERT 可以根据分段捕获上下文。如:记号往往比其他段落中的记号关注更多。另一方面,BERT 模型似乎更加关注它的邻居: 图5(a)中在主对角线周围可以看到一条带状的轮廓线。从图5(f)和图5(c) ,可以看到最后一层的注意力结构不同于浅层,SegaBERT 比 BERT 更关注它的上下文。 上述表明: 在浅层中,作者的模型是段感知的,而 BERT 是邻居感知的; 在顶层中,这两个模型都关注文章中的某些标记,而不是相邻的词,但是论文中的模型可以捕获更多的上下文标记。
5、结论
在本论文中,提出了一种新的分段感知Transformer、可以编码丰富的位置信息的语言建模。将方法应用于 Transformer-XL,在 WikiText-103上训练了一个新的语言模型 Segatron-XL,实现了17.1的ppl。另外,用 SegaBERT 方法对 BERT 进行了预训练,结果表明模型在一般语言理解、句子表征学习和机器阅读理解任务方面优于 BERT 模型。