1、摘要
Transformer不适合处理长文件输入,因为,随着文本长度的增加,消耗的内存和时间是N2的指数级增加。也有很多学者,通过截断一个长文档或应用稀疏注意机制,在一定程度上可以解决上下文碎片问题,但起到的作用有限。在这篇文章中,作者提出了一个预训练语言模型 ERNIE-DOC,是一个基于Recurrence Transformers(Dai et al., 2019) 的文档级语言预训练模型。 本模型用了两种技术:回溯式feed机制和增强的循环机制,使模型 具有更长的有效上下文长度,以获取整个文档的相关信息。作者做了英语和汉语文档级任务的各种实验。在 WikiText-103上实现了16.8 ppl 的 SOTA 语言建模结果,在文本分类、问答等语言理解任务上表现优于其他竞争性的预训练模型。
2、拟解决问题
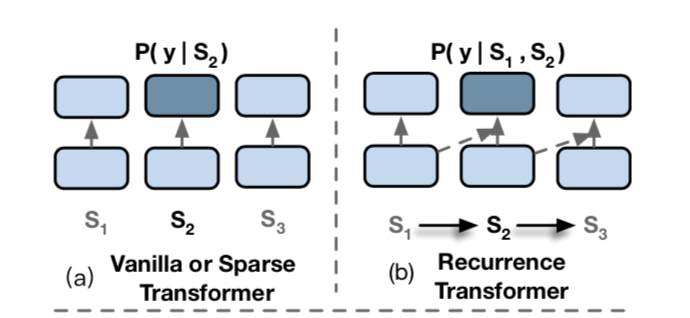 现有的稀疏注意和截断的策略不是那么有效,因为,在训练过程中,对于每个片段而言,整个文件的背景信息仍然是不可用的,如上图所示,Vanilla or Sparse Transformer结构只能利用单个片段的信息去预测y,Recurrence Transformer结构可以利用S1和S2去预测y,但是利用不了S3的信息,所以需要一个更好的方法去改善它。
现有的稀疏注意和截断的策略不是那么有效,因为,在训练过程中,对于每个片段而言,整个文件的背景信息仍然是不可用的,如上图所示,Vanilla or Sparse Transformer结构只能利用单个片段的信息去预测y,Recurrence Transformer结构可以利用S1和S2去预测y,但是利用不了S3的信息,所以需要一个更好的方法去改善它。
3、ERMIE-DOC
- 背景
我们先看一下之前的模型是怎么捕获知识的。 从下面公式可以看出,Vanilla 和 Sparse Transformers没有利用之前片段的信息。而Recurrence Transformers(Transformer-XL),利用了当前层上一个时间步的信息。即memory。h_τ+1利用的是上层当前τ+1时间步的隐层状态。因此,正如图1所示,S3最多只能利用到S1,S2的片段信息。这说明,Recurrence Transformer能最大利用的信息有限。 其中,SG表示不计算梯度。
其中,SG表示不计算梯度。 - Retrospective Feed Mechanism
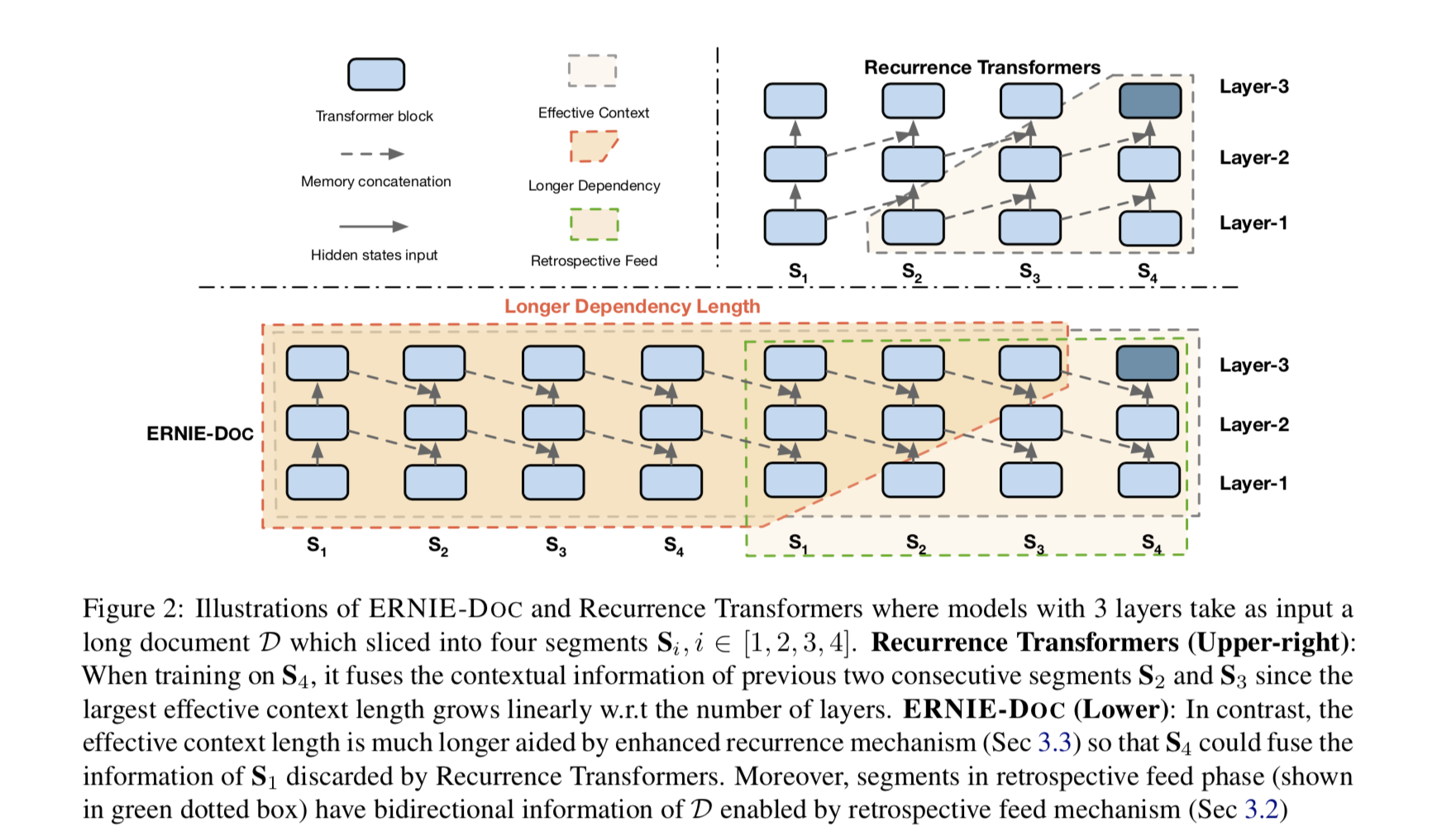
框架图如上所示
Retrospective Feed Mechanism是ERMIE-DOC用到的关键算法之一。这个算法的灵感来源于,人在读文章时,在读完第一遍之后,可能并没有太理解一些地方,然后人会在读完整篇之后,回过来继续精读某一个部分。也就是说,先略读一遍,在精读部分。ERMIE-DOC的这个算法就是仿照这个原理来的。公式如下
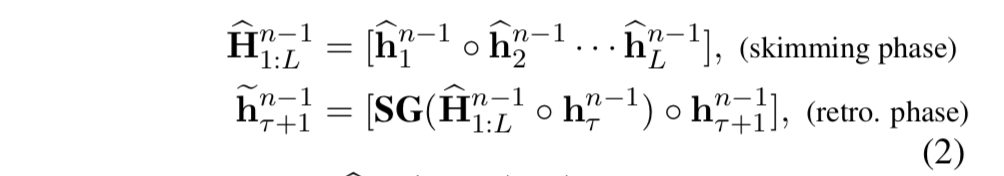 第一个公式表示略读阶段,h1,h2,...hL值得是文章的每个Token的隐层向量。之后,将这整篇文章的向量和当前时间步的上一个时间步的隐层向量进行拼接作为memory。在和当前时间步的hτ+1进行拼接。得到当前时间步的向量。但是如果这样的话,hτ+1在句子维度上会很大。因此,作者就想了另外一个方案。因为每个时间步的hl向量,都和上一个时间步的hl-1有交互,所以,作者认为,这样就不需要将之前的所有时间步的h拿过来,只需要拿几个就行。比如,每隔n步取一个h,得到的向量就是一个公差为n的等差数列,这样极大的缩短了memory的长度。
第一个公式表示略读阶段,h1,h2,...hL值得是文章的每个Token的隐层向量。之后,将这整篇文章的向量和当前时间步的上一个时间步的隐层向量进行拼接作为memory。在和当前时间步的hτ+1进行拼接。得到当前时间步的向量。但是如果这样的话,hτ+1在句子维度上会很大。因此,作者就想了另外一个方案。因为每个时间步的hl向量,都和上一个时间步的hl-1有交互,所以,作者认为,这样就不需要将之前的所有时间步的h拿过来,只需要拿几个就行。比如,每隔n步取一个h,得到的向量就是一个公差为n的等差数列,这样极大的缩短了memory的长度。
1. Enhanced Recurrence Mechanism
加强的自循环机制。其实就是将上一层前一时间步的向量拿过来(Recurrence Mechanism)-> 将当前层的前一时间步向量拿过来。公式如下:
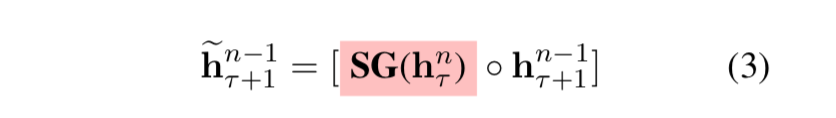 2. 预训练任务
2. 预训练任务
a) MLM
这个就是BERT的mask的预测任务。
loss就是预测mask位置的Token。
b) Segment Reordering Objective
任务之一:将一篇文章的每个大片段如[C1, C2, C3]随机打乱 - > [C2, C1, C3]等,然后进行恢复。如果分词了3个大片段,就是一个3分类,如果分成4个大片段,就是6分类。
任务之二:将[C1, C2, C3]继续拆分为小片段 -> [S0, S1, ..., Sn]。然后进行恢复。也是一个n的组合问题。
Loss函数:
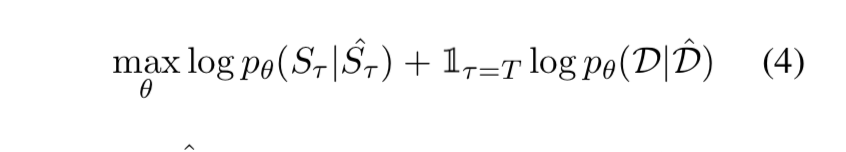 总的loss就是上述两部分的loss之和。
总的loss就是上述两部分的loss之和。
4、 结果
a) 预训练语言模型对比
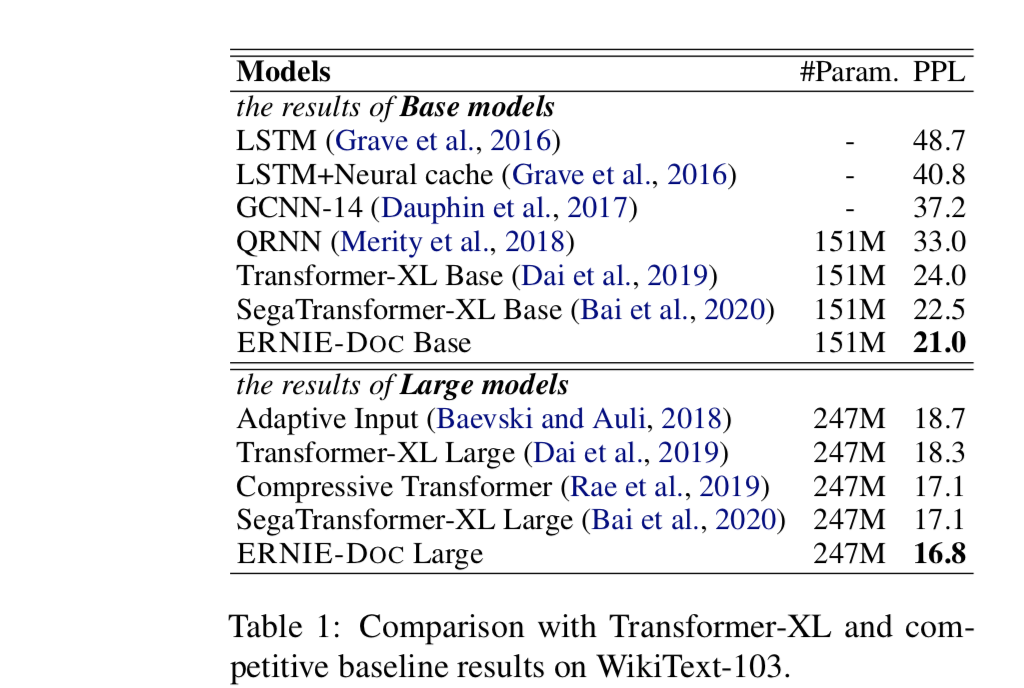
本论文采用WikiText-103作为训练数据,然后进行ppl测试。在和Transformer-XL模型对比。但是这部分的结构和最终的ERNIE-DOC不太一样。和XL对比只是将Recurrence Mechanism改成了Enhanced Recurrence Mechanism,即XL是采用上一层的前一个片段的输出作为memory。而现在改进之后,是采用当前层的前一个片段的输出作为memory。这样的话,就可以利用到很长的历史了。从Figure2可以明显看出。除了这个之外,本文对XL的改进还引入了(Bai et al., 2020)这篇文章的片段感知编码方法(将段,句,Token分别编码)。结果如下表。可以看到加入片段感知和Enhanced Recurrence Mechanism之后,ERNIE-DOC的base模型的PPL降低至21,large模型降低至16.8,相比(Bai et al., 2020)的17.1分别降低了1.5,0.3个PPL,而相比原始的Transformer-XL,分别降低了3,1.4个PPL。效果还是不错的。
b) 下游任务Finetune
英语预训练模型采用的语料如表2所示。中文语料采用的和ERNIE2.0一样。这个模型和之前对比的XL模型不太一样,融合了之前讲的所有的改进:MLM + Segment Reordering Objective两个预训练任务。
之后进行下游任务Finetune对比。
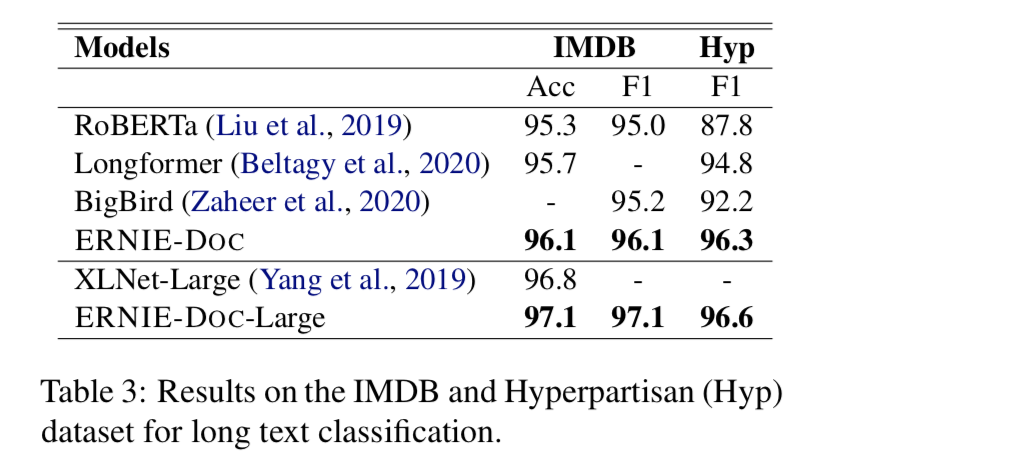
- IMDB和Hyp数据集
长文本分类数据集,相比之前的模型,都是sota。
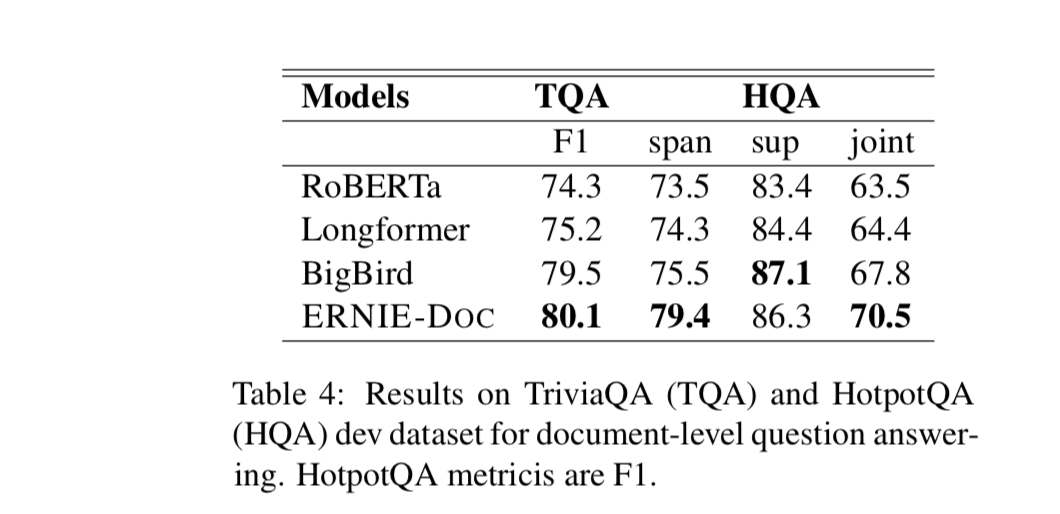
- TQA和HQA
文档级问答数据集,除了HQA的sup指标,都是sota。
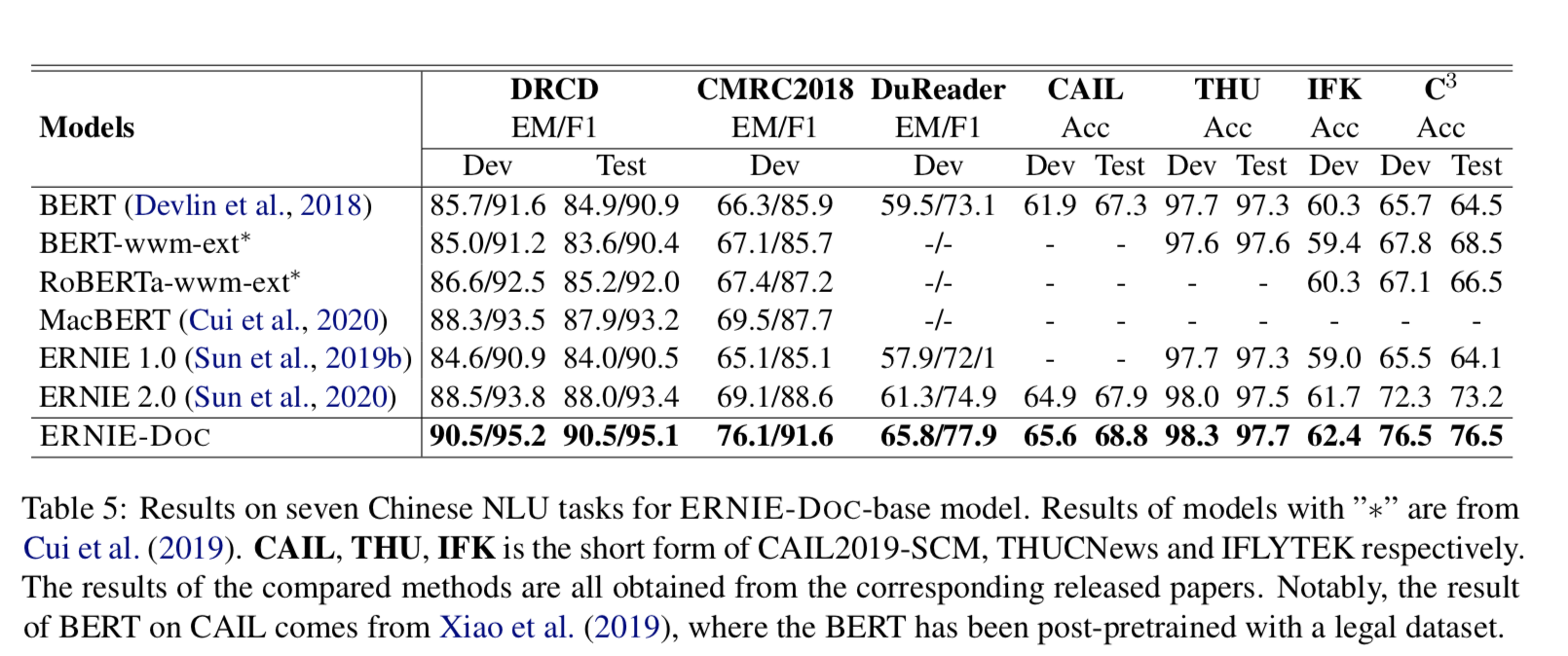
- 七个中文NLU任务
base模型,都是sota。中文的下游任务,做的模型不多。相对于英文,拿到sota相对容易一些,但是本文方法的还是值得夸赞的。
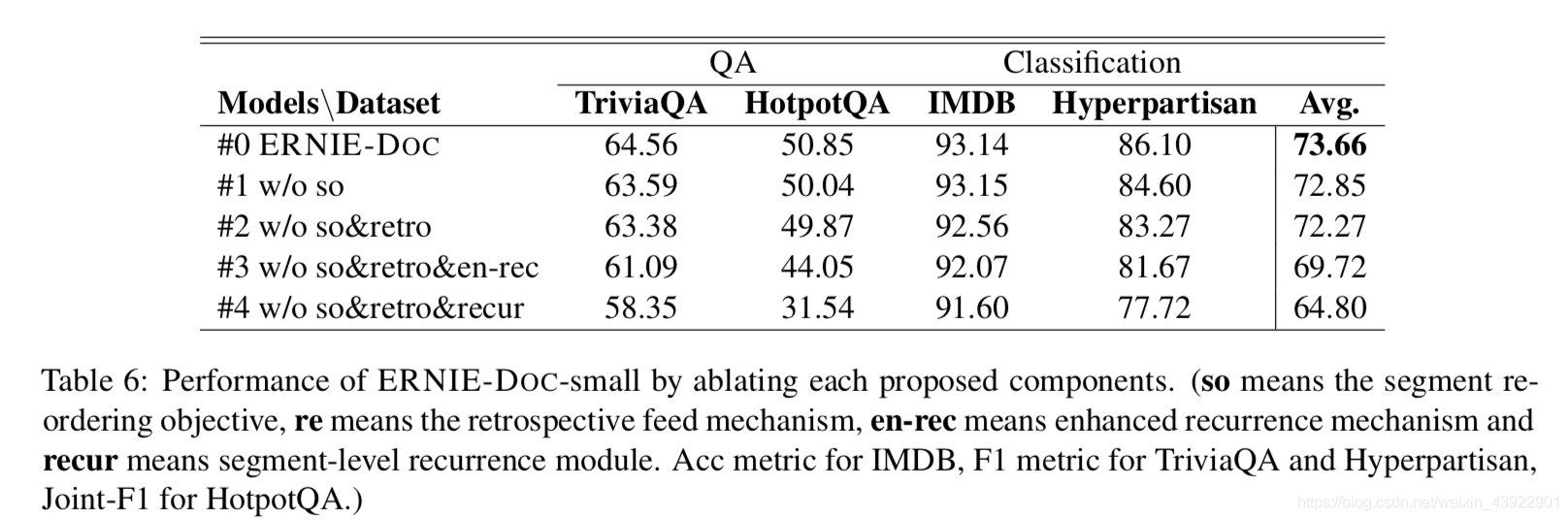
5、消融实验
对比了下0-segment reordering objective,1-retrospective feed mechanism, 2-recurrence mechanism,3-enhanced recurrence mechanism等子模块的作用大小。其中:0,1,2,3表示子模块的编号。
- #0:0 + 1 + 2 + 3
- #1:1 + 2 + 3
- #2:2 + 3
- #3:2
- #4: 都没有
从下表最后一列可以看出,片段重排目标平均提高了 ERNIE-DOC 0.81个百分点(# 1-# 0) ,回溯推送机制平均提高了 ERNIE-DOC 0.58个百分点(# 2-# 1) ,增强循环机制平均提高了2.55个百分点(# 3-# 2)。通过比较 # 3和 # 4,我们看到循环机制对于建模平均提高4.92% 的长文档是必要的。考虑到不同类型的任务,我们观察到Hyperpartisan——极长的文本分类数据集,得到了良好的改进使用片段重排序目标(1.5% 点) ,表明预训练使用片段重排序目标更适合于一个更相同的文本级别的文本分类任务。此外,通过使用增强的循环机制,可以看到所有任务都获得了稳定的性能提升。
6、结论
本文提出了一种基于Recurrence Transformer的文档级语言预训练模型 ERNIE-DOC。采用了两种设计算法,即retrospective feed mechanism 和 enhanced recurrent mechanism ,使 ERNIE-DOC 具有理论上最长的可能依赖性,能够对整个文档的双向上下文信息进行建模。此外,ERNIE-DOC 预先训练了一个文档感知部分重新排序目标,以明确学习长上下文各部分之间的关系。对各种下游任务的实验表明,ERNIE-DOC 比以前的强大预训练模型(如 RoBERTa,Longformer,BigBird by a large mar-gin)性能更好,并且在几个语言建模和语言理解基准测试中取得了最好的结果。