1、摘要
这篇论文主要研究了数据集上如何有效地使用 BERT finetune问题,首先,论文提到在BERTADAM 优化器中遗漏了梯度偏差校正,不利于模型的finetune,尤其是在小数据集上,训练初期,模型会持续震荡,进而会降低整个训练过程的效率,减慢收敛的速度,导致微调不稳定性。其次,BERT 网络的某些部分为微调提供了一个不利的训练起点,并且通过简单地重新初始化这些层可以加速学习并提高性能。最后,提到了训练时间的影响,并观察到常用的方法往往没有分配足够的时间进行训练,就是没有训练完全,需要增大训练步数。基于这些问题,作者对其进行了改进,并重新评估性能情况,模型的性能得到了较大的提升。
2、创新点
- 提出BERTAdam优化器未进行动量偏差修正;
- BERT中,小数据集怎么更有效的进行finetune。
3、实验细节
3.1、Adam的debiasing影响

首先,看下BERT的BERTAdam和Adam优化器部分源码:
BERTAdam
next_m.mul_(beta1).add_(1 - beta1, grad)
next_v.mul_(beta2).addcmul_(1 - beta2, grad, grad)
update = next_m / (next_v.sqrt() + group['e'])
if group['weight_decay_rate'] > 0.0:
update += group['weight_decay_rate'] * p.data
if group['t_total'] != -1:
schedule_fct = SCHEDULES[group['schedule']]
lr_scheduled = group['lr'] * schedule_fct(state['step']/group['t_total'], group['warmup'])
else:
lr_scheduled = group['lr']
update_with_lr = lr_scheduled * update
p.data.add_(-update_with_lr)
state['step'] += 1
Adam
beta1, beta2 = group['betas']
state['step'] += 1
bias_correction1 = 1 - beta1 ** state['step'] # 偏差修正
bias_correction2 = 1 - beta2 ** state['step'] # 偏差修正
if group['weight_decay'] != 0:
grad.add_(group['weight_decay'], p.data)
exp_avg.mul_(beta1).add_(1 - beta1, grad)
exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)
if amsgrad:
torch.max(max_exp_avg_sq, exp_avg_sq, out=max_exp_avg_sq)
denom = (max_exp_avg_sq.sqrt() / math.sqrt(bias_correction2)).add_(group['eps'])
else:
denom = (exp_avg_sq.sqrt() / math.sqrt(bias_correction2)).add_(group['eps'])
step_size = group['lr'] / bias_correction1
p.data.addcdiv_(-step_size, exp_avg, denom)
可以看到,在BERTAdam中,并没有进行动量偏差修正,因此在模型训练初期以及指数衰减率超参数(β)很小的时候,动量估计值很容易往0的方向偏移,具体看推导:

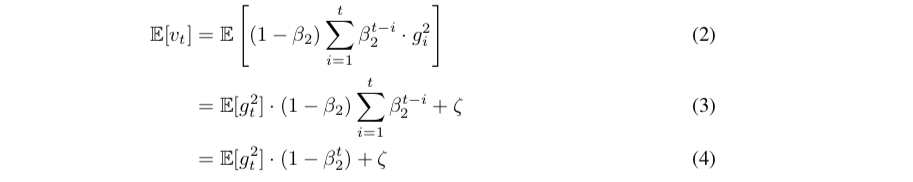 当二阶动量是一个稳态分布时,在每个时刻t上它都是一个常量,因此 ζ 为0。E[g] 后面的部分为一个等比数列求和即可。
当二阶动量是一个稳态分布时,在每个时刻t上它都是一个常量,因此 ζ 为0。E[g] 后面的部分为一个等比数列求和即可。
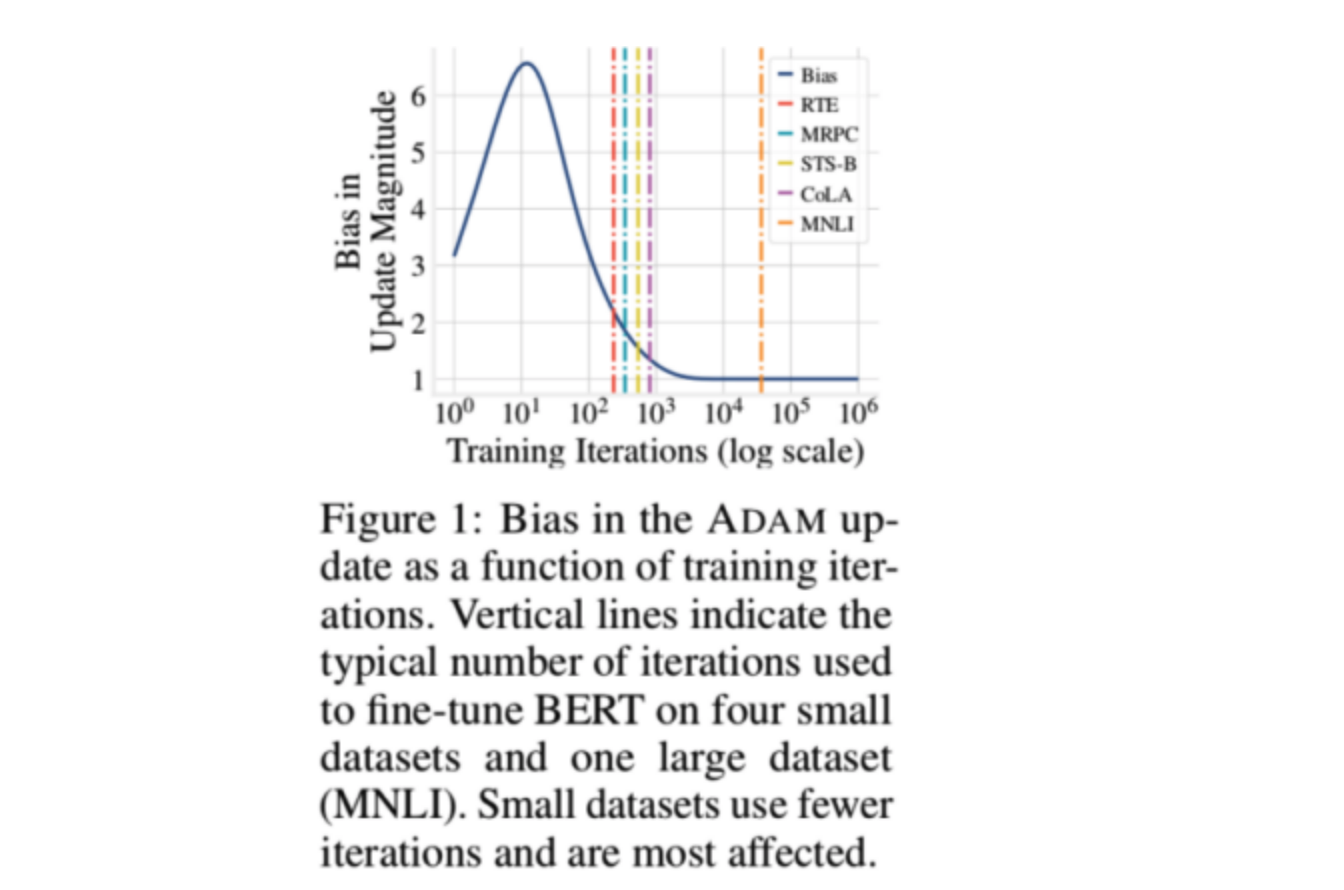
- mt / √ vt 和数据量的关系
文章用了四个小数据集和一个大数据集在Bert上进行finetune,然后对比了某个特定训练步数下的Bias的值,这个实验的目的主要是说明在小数据集上,Bias会更大一些,从而使得训练会更不稳定。
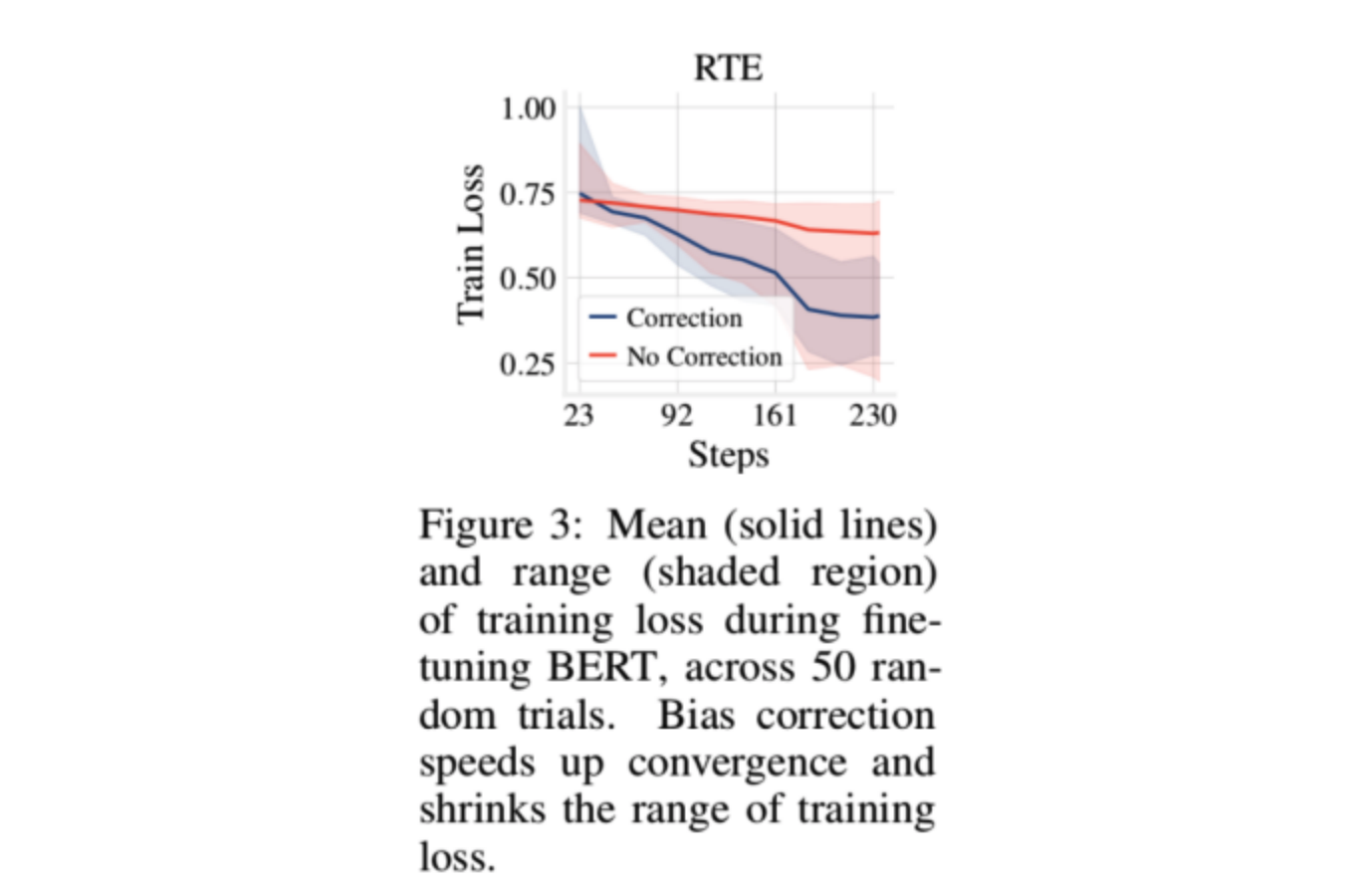
- 对比偏差修正在小数据集上的loss影响 这个实验用的RTE数据集,数据集较小,主要是为了研究Adam加入偏差修正在小数据集上的影响情况,为了防止偶然误差,实验用了50个随机种子,最后取平均得到的结果。可以看到,加入偏差修正后,模型收敛更快了,验证了之前的假设。
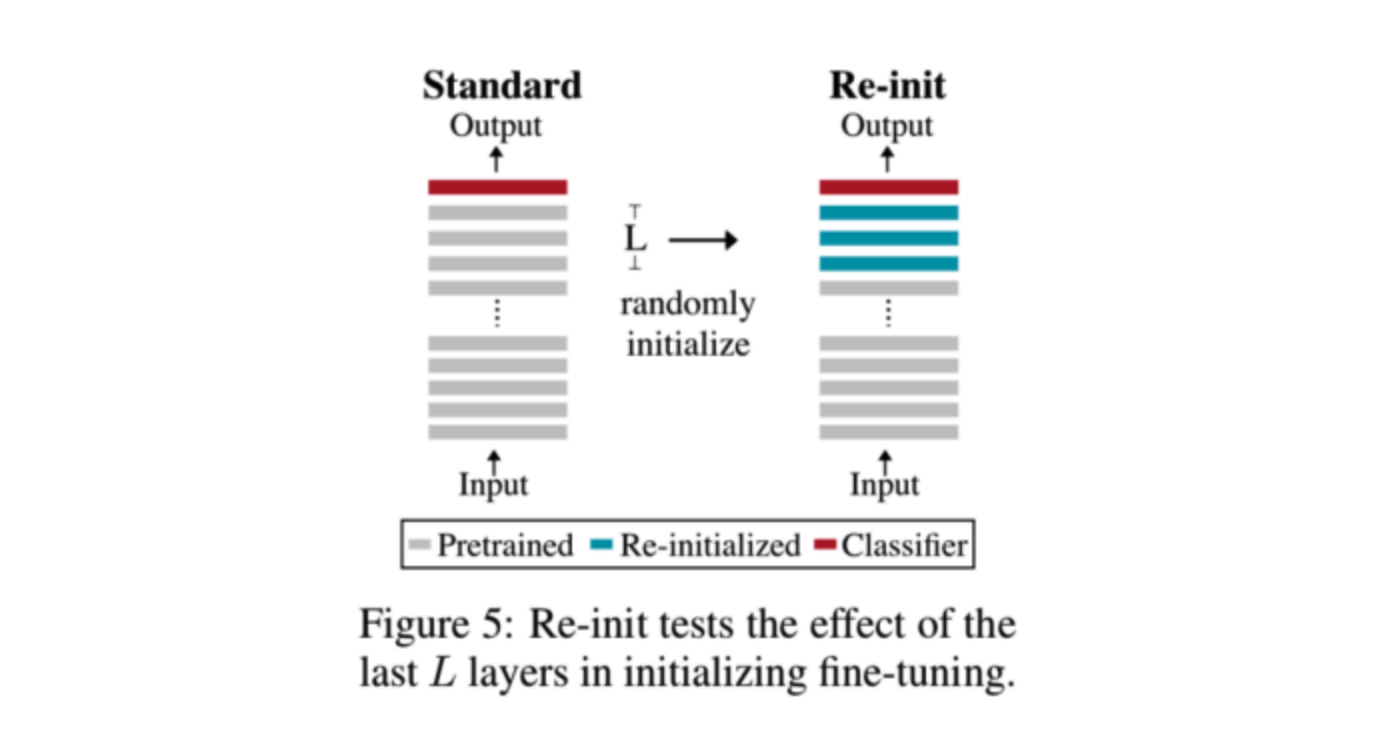
3.2、初始化预训练层的影响
这部分作者主要针对Bert初始化参数的方式做了一下探讨,之前很多学者就已经证明,Bert模型在低层和高层学习到的信息是不一样的,在底层,模型主要学习一些语义上的信息,而在高层,学的主要是和任务相关的信息。因此,论文在选择初始化层的时候,就丢弃了高层的任务相关的信息,保留语义信息,然后进行finetune。
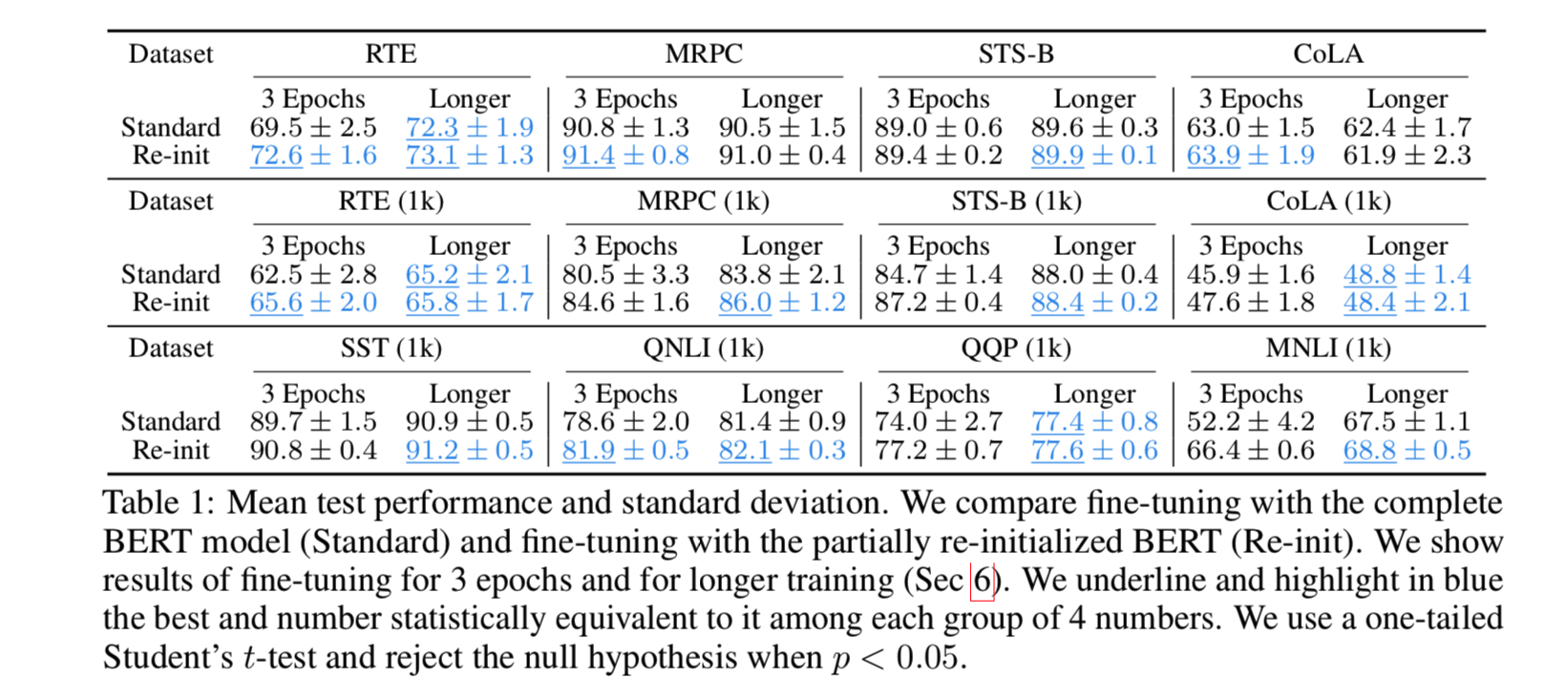
 论文基于12层的Bert,对Top6层进行随机初始化,在RTE,MRPC等数据集上进行finetune,结果如下表所示,结果很明显,相对于完全使用Bert进行初始化,部分初始化对最后模型的性能都有一定程度的提升。
论文基于12层的Bert,对Top6层进行随机初始化,在RTE,MRPC等数据集上进行finetune,结果如下表所示,结果很明显,相对于完全使用Bert进行初始化,部分初始化对最后模型的性能都有一定程度的提升。
 - 参数初始化的影响结果
- 参数初始化的影响结果
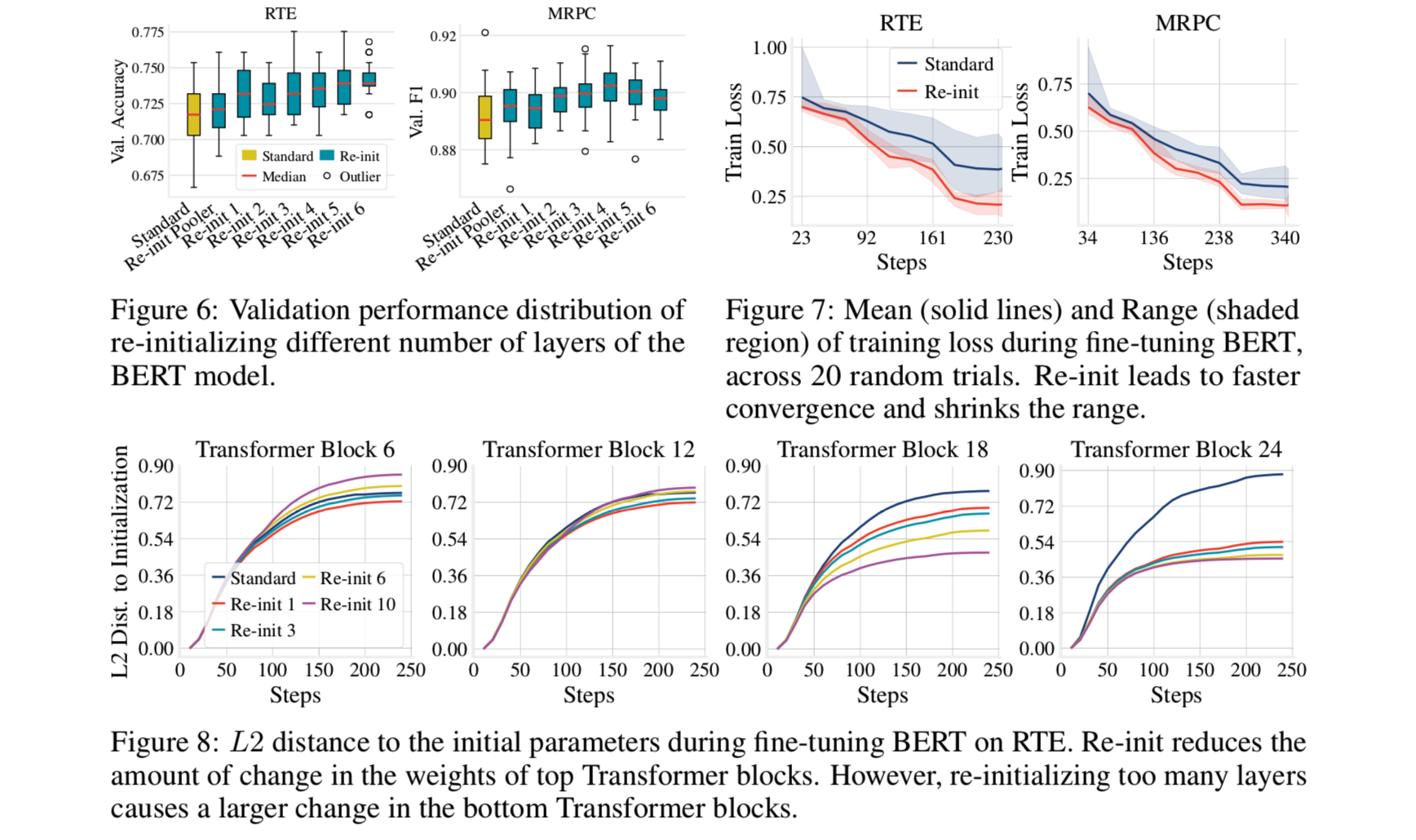
这部分就不详细说明了,简单总结以下几点: ①figture 6:说明随机初始化topN(N<6)层或多或少都能提升模型的性能; ②figture 7:说明随机初始化topN某些层,能加快模型收敛速度; ③figture 8:说明随机初始化topN某些层,对高层的参数改变的更小,但随着N的增大,比如N=10,会使得底层的参数改变严重
3.3、finetune更长的step
训练更长的时间有利于提高模型的性能,特别是数据集小于1000时。结果在tabel 1中。
4、结论
- 指出 BERTADAM 中的去偏漏洞使得Bert在小数据集上模型性能不好的的主要原因。
- 观察预训练的 BERT 的顶层为finetune和收敛速度提供了一个有害的初始化。简单地重新初始化这些层不仅可以加速学习,而且可以提高模型的性能。
- 延长finetune bert训练时间可以使得微调趋于稳定。