Learning Spatio-Temporal Transformer for Visual Tracking
论文地址:https://arxiv.org/abs/2103.17154
1、参考初衷
近来由于Transformer在NLP领域实现的强大功能和持续进展,在CV领域也越来越关注着一模型框架,并出现了很多利用、改造Transformer用于图像处理的尝试,本文就是其中的一种尝试。
选取本文,是其并没有采取改造Transformer内部结构等复杂操作来适应图像领域,而是比较简洁的在过程中嵌入,在逻辑上保持了Transformer从NLP迁移过来的完整性,从而有性能和质量保证,同时降低了迁移成本。
在嵌入模型中,采用CNN + Transformer的结构也非常直观清爽有效,从而让模型在视觉追踪任务做到了简洁和高效。
2、摘要
在本文中,我们提出了一种新的跟踪结构,以编码器-解码器变压器为关键部件。编码器模拟目标对象和搜索区域之间的全局时空特征依赖关系,解码器学习嵌入式查询来预测目标对象的空间位置。我们的方法将目标跟踪作为一个直接的边界盒预测问题,不使用任何建议或预定义的锚。使用编码器-解码器变 换器,对目标的预测仅仅使用一个简单的全卷积网络,它直接估计目标的角落。整个方法是端到端的,不需要任何后处理步骤,如余弦窗口和边界盒平滑,从而大大简化了现有的跟踪管道。提出的跟踪器在五个具有挑战性的短期和长期基准上达到了最先进的性能,同时以实时速度运行,比 Siam R-CNN 快 6 倍。代码和模型在这里是开源的。
3、背景
视觉追踪是在一个图像时间序列流里,检测目标物体并给出目标位置。对这个任务,及要求物体类别的识别准确性和物体位置识别的准确性,同时保证处理速度(帧率)比较高。
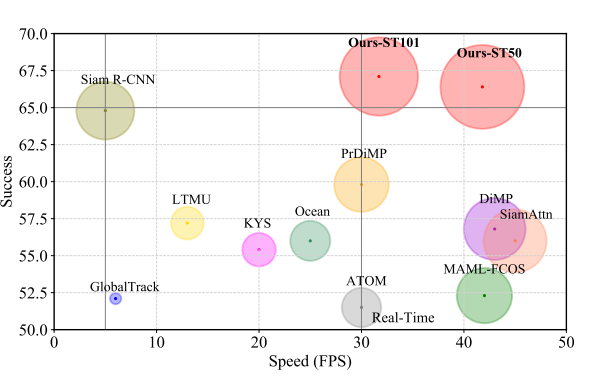
空间和时间信息对目标跟踪都很重要。前者包含目标定位的对象外观信息,而后者包含对象在帧间的状态变化。以前的跟踪器只利用空间信息进行跟踪,而在线方法使用历史预测进行模型更新。尽管取得了成功,但这些方法并没有明确地模拟空间和时间之间的关系。本文考虑到全局依赖建模的优越性,采用Transformer将空间和时间信息进行集成进行跟踪,生成区分时空特征进行目标定位。
4、实现
4.1 单帧任务
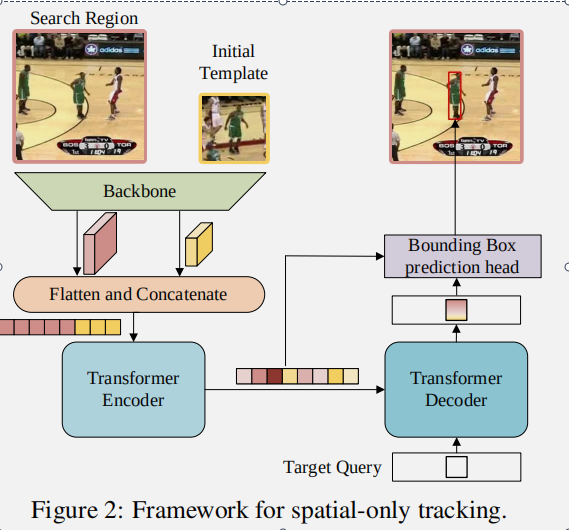
模块组成:
- 骨干卷积网络
- Transformer 编码器-解码器
- 边界预测框
骨干卷积网络: 可以使用任意卷积网络作为特征提取的骨干。在不失一般性的情况下,文章采用香草ResNet(一种ResNet)作为骨干。更具体地说,除了去除最后一个阶段和完全连接层之外,原来的ResNet没有其他变化。ResNet是一个纯CNN结构,并且这里是预训练好的一个图像模型,在输入单帧图片和初始检索框的时候,这个ResNet会作为特征提取器,特征维数为:fz ∈ RC× Hsz × Wsz 和 fx ∈ RC× Hsx × Wsx 。
Transformer编码器:主干网的特征映射输出需要在输入编码器之前进行预处理。具体来说,瓶颈层首先用于减少通道数量从 c 到 d。然后按照 d 的空间维度、前维度和维度对特征映射进行平滑和连接,作为变压器编码器的输入。编码器由 n 个编码器层组成,每个编码器层由一个带有前馈网络的多头自我关注模块组成。由于原始Transformer的置换不变性,我们向输入序列添加正弦位置嵌入。编码器捕获序列中所有元素之间的特征依赖系,并用全局上下文信息加强原始特征,从而允许模型学习对象定位的判别特征。
Transformer解码器:解码器接受目标查询和来自编码器的增强特征序列作为输入。与 DETR 采用100个对象查询不同,我们只输入一个检索到解码器中来预测目标对象的一个边界框。此外,由于只有一个预测,我们删除了 DETR 中用于预测关联的匈牙利算法。与编码器类似,解码器堆叠 m 个解码器层,每个解码器层包括一个自注意、一个编码器-解码器注意和一个前馈网络。在编解码注意模块中,目标查询可以注意模板上的所有位置和搜索区域特征,从而学习最终包围盒预测的鲁棒表示。
训练和推理:正如最近的本地化和分类的联合学习可能会导致这两个任务的次优解决方案,它有助于解耦定位和分类。因此,我们将培训过程分为两个阶段,以本地化为主要任务和分类具体来说,在第一阶段,我们会把这项工作列为次要工作整个网络,除了记分头,是训练端到端只与本地化相关的损失在公式。第二阶段,确保所有搜索图像都包含目标对象,并让模型学习定位能力。
loss:
- IoU loss:L = λiouLiou(bi, ˆbi) + λL1 L1(bi, ˆbi)
- binary cross-entropy loss:Lce = yilog (Pi) + (1 − yi)log (1 − Pi)
4.2 多帧任务

与仅使用第一帧和当前帧的基线方法不同,时空方法引入了从中间帧取样的动态更新模板作为附加输入,除了来自初始模板的空间信息之外,动态模板可 以捕获目标外观随时间的变化,提供额外的时间信息。类似于单帧任务中的基线架构,三元组的特征映射被压平并连接起来,然后发送给编码器。编码器通过建模空间和时间维度中所有元素之间的全局关系来提取歧视性的时空特征。
结论
文章提出了一种新的基于变压器的跟踪框架,该框架能够在空间和时间维度上捕获长距离的依赖关系。此外,提出的STARK 跟踪器去除了超参数敏感的后处理,导致一个简单的推理流水线。大量的实验表明,STARK 跟踪器在五个短期和长期基准上的表现要比以前的方法好得多,而且是实时运行的。我们希望这项工作能够吸引更多关注视觉跟踪的变压器架构。
个人总结:
1、文章结合CNN和Transformer的一大亮点是,用预训练好的ResNet作图像特征提取器,经过转换后给Transformer处理。特别大的好处时:保证了图像特征的有效获取,发挥了CNN和Transformer各自的特长。同时预训练也减少了图像处理的计算量,在训练Transformer时也规避了数据集小和CNN训练不稳定可能导致的冲突问题。
2、视觉跟踪、天气预测等时间序列任务,对时间信息的处理都很重要。本文利用动态更新框来缓存更新时间信息,作为一个特征输入给予Transformer。很简洁高效,值得借鉴。