1 前言
随着2018年底Bert的面世,NLP进入了预训练模型的时代。各大预训练模型如GPT-2,Robert,XLNet,Transformer-XL,Albert,T5等等层数不穷。但是几乎大部分的这些模型均不适合语义相似度搜索,也不适合非监督任务,比如聚类。而解决聚类和语义搜索的一种常见方法是将每个句子映射到一个向量空间,使得语义相似的句子很接近。说到这,可能有的人会尝试将整个句子输入预训练模型中,得到该句的句向量,然后作为句子的句向量表示。但是这样得到的句向量真的好吗?在论文《Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks》就指出了,这样得到的句向量不具有语义信息,也就是说,两个相似的句子,得到的句向量可能会有很大的差别。此外,不仅句向量表示的语义方面存在很大差别,而且,它要求两个句子都被输入到网络中,从而导致巨大开销:从10000个句子集合中找到最相似的sentence-pair需要进行大约5000万个推理计算(约65小时),因此,这种方案不太友好。
2 解决的问题
面对上述预训练模型在文本语义相似度等句子对的回归任务上的问题,本文提出了Sentence-BERT(SBERT),对预训练的BERT进行修改:使用孪生(Siamese)和三级(triplet)网络结构来获得语义上有意义的句子embedding,以此获得定长的sentence embedding,使用余弦相似度或Manhatten/Euclidean距离等进行比较找到语义相似的句子。通过这样的方法得到的SBERT模型,在文本语义相似度等句子对的回归任务上吊打BERT , RoBERTa 拿到sota。 那么接下来看下论文是怎么做的。
3 网络结构
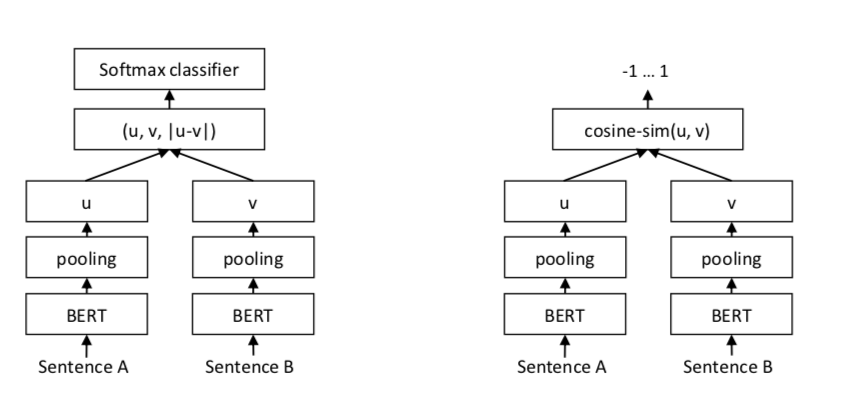 其中左图是训练的模型,右图是训练好模型之后利用句向量计算2个句子之间的相似度。u,v分别表示输入的2个句子的向量表示,|u-v|表示取两个向量的绝对值,(u, v, |u-v|)表示将三个向量在-1维度进行拼接,因此得到的向量的维度为 3*d,d表示隐层维度。
其中左图是训练的模型,右图是训练好模型之后利用句向量计算2个句子之间的相似度。u,v分别表示输入的2个句子的向量表示,|u-v|表示取两个向量的绝对值,(u, v, |u-v|)表示将三个向量在-1维度进行拼接,因此得到的向量的维度为 3*d,d表示隐层维度。
4 训练
使用SNLI和NLI数据集对Bert和Roberta进行fine-tune,得到SBERT预训练模型。
Polling策略
① mean:将句子的所有token在token维度上计算平均,这样就可以得到768(base)/1024(large)维度向量;
② max:将句子的所有token在token维度上的最大那个值,即做maxovertime,这里多解释下maxovertime,就是比如x = torch.randn(2, 10, 20),就是取x.max(1);
③ CLS:就是原始Bert做分类的方法,取句子的第一个token的向量。 作者发现,使用mean的效果最好,max最差。loss函数
① 回归任务:softmax,均方差损失函数;
② 分类任务:softmax, 交叉熵损失函数;
③ Wikipedia section triplets dataset (Dor et al., 2018)(三句分类任务):这个数据集是一些书中的句子,每一条数据有三句话,其中两句来自同一个章节的句子,另外一句是这本书的另外一个章节。
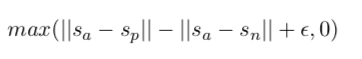
其中 ε设为1,||a, b||表示a和b的距离。求该损失函数的目的就是使得,a和p的距离小于a和n的距离。Encoder之后特征提取策略
](https://img-blog.csdnimg.cn/20200509142134913.png?x-ossprocess=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MzkyMjkwMQ</mark>,size_16,color_FFFFFF,t_70)
最后发现使用(u, v, |u-v|)效果最好。
训练速度
在CPU, InferSent比SBERT块65%,在GPU上,论文使用了Smart batching策略,即将长度差不多的句子放在一个Batch训练,用这种方法在CPU上提升了89%,在GPU上提上了48%。此外,速度比inferSent快5%,比Universal Sentence Encoder快55%。其他细节
学习率:2e-5; warmup:0.1; batchsize:16;优化器:Adam。
5 结论
STS数据集
直接使用SBERT进行预测。
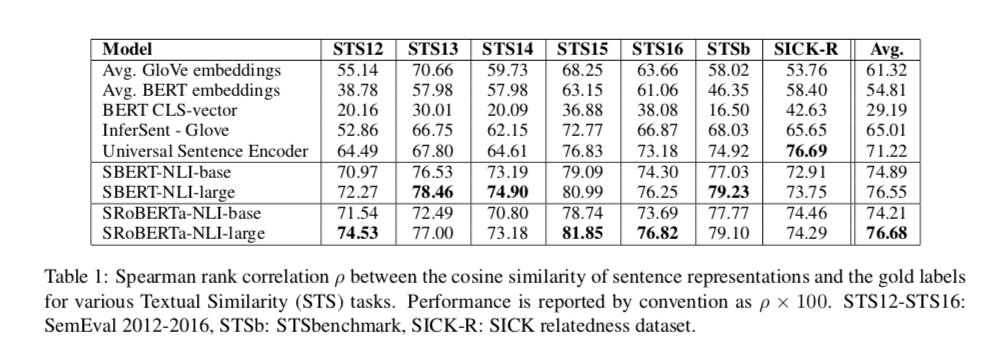 从表中可以看到,使用SBERT的效果远远好于BERT
从表中可以看到,使用SBERT的效果远远好于BERT
注意:表格中的SBERT-NLI-base其实就是文章中的SBERT,意思是使用SNLI和NLI数据集对BERT进行fine-tune得到的预训练模型。
- #### NLI + STSb两步训练
即使用STSb数据集对SBERT进行fine-tune
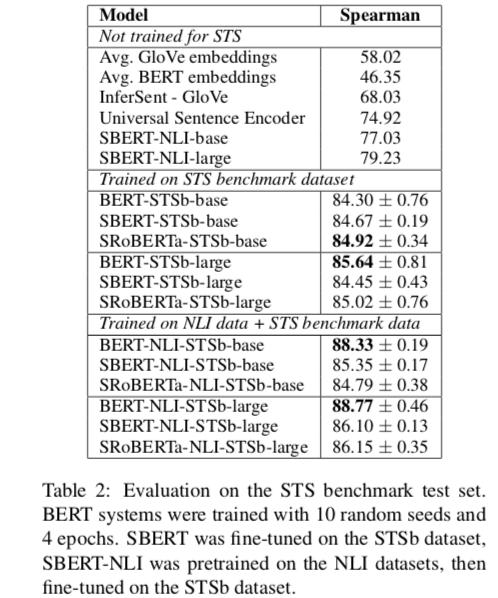
从表中可以看到,当使用了STSb数据对SBERT进行fine-tune(bert-base:88.33)后,比直接使用SBERT评测STSb(77.03)效果好得多
AFS(Argument Facet Similarity)数据集
该数据集包含gun control, gay marriage, and death penalty三个话题。论文使用了其中两个主题A,B作为训练数据,另外一个C主题数据作为测试。最后取平均分数。结果如下:
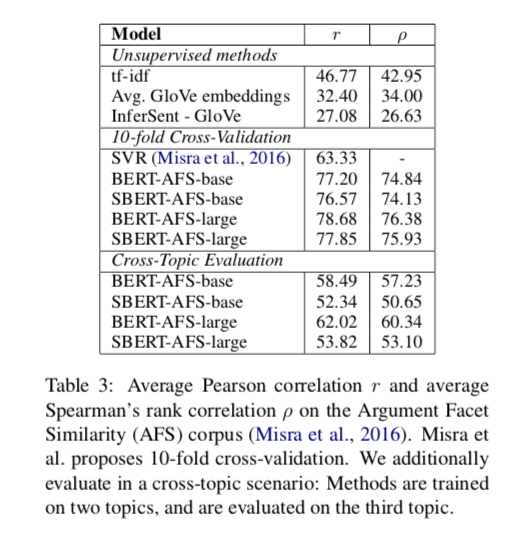
从表中可以看到,对比于Glove和tf-idf均有很大的提升,但是对于Bert,不论是10倍交叉验证还是正常评测,效果反而下降了。
论文提到,这个是由于训练的主题数据太少,导致在得到没有见过的主题时,性能不如Bert。
Wikipedia section triplets dataset
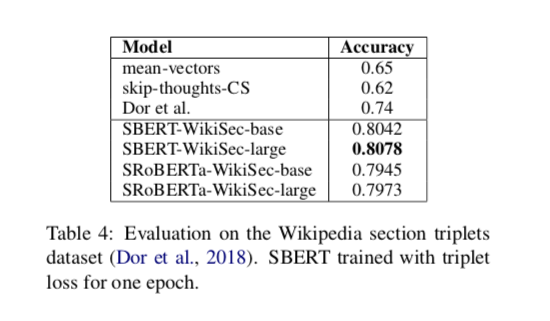 从表中可以看到,对比于Dor et al论文的方法有很大的提升。
从表中可以看到,对比于Dor et al论文的方法有很大的提升。句向量评测 SentEval
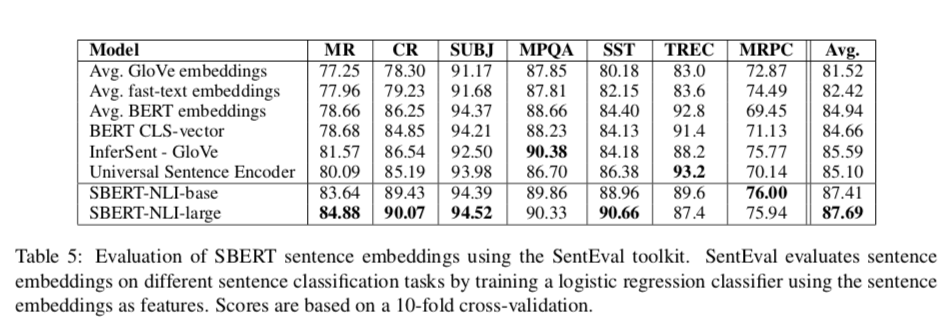
从表中可以看到,对比于Glove,BERT和Universal Sentence Encoder,SBERT在大部分词向量评测上也是sota。
总之,SBERT的方法可以很好的用于语义相似度和句子对分类和一些回归的任务上,均能取得不错的效果。 论文链接:https://arxiv.org/abs/1908.10084