1、摘要
基于 transformer 的模型的巨大成功得益于强大的多头自我注意机制,该机制从输入中学习token依赖并编码语境信息。先前的工作主要致力于针对具有不同显著性度量的单个输入特性的贡献模型决策,但是他们没有解释这些输入特性如何相互作用以达到预测。这篇论文就提出了一种用于解释Transformer内部信息交互的自注意属性算法ATTATTR。文章以 BERT 模型为例进行了以下实验:
(1)提取各层最依赖关系,构造属性图,揭示Transformer内部的层次交互;
(2)用自我注意归因来识别重要的注意头,而其他的可以被裁剪,只有边际的性能退化;
(3)证明了归因结果可以作为对抗模式来实施对 BERT 的非目标攻击。
2、创新之处
提出了一种用于解释Transformer内部信息交互的自注意属性算法ATTATTR。
3、实验
3.1 归因
归因?可能很多同学对这个词有点陌生,网上的解释:指人们对他人或自己行为原因的推论过程。 具体的说,就是观察者对他人的行为过程或自己的行为过程所进行的因果解释和推论。 文章中的归因意思大致相同,只不过这个对象不是人,而是模型的预测结果,即模型预测的结果的产生原因。比如将下图输入给分类模型。
 预测结果可能为猫,狗,鸟等等,预测每一个类别都会被某个/某些特征所决定,比如体型,眼睛等等。这些就是其预测结果的归因。这篇论文就是结合归因,得出某些token的归因分数,并进行可视化,让我们能够更加形象看到结果是由哪些原因造成的。那么这个归因分数是怎么计算的呢?
预测结果可能为猫,狗,鸟等等,预测每一个类别都会被某个/某些特征所决定,比如体型,眼睛等等。这些就是其预测结果的归因。这篇论文就是结合归因,得出某些token的归因分数,并进行可视化,让我们能够更加形象看到结果是由哪些原因造成的。那么这个归因分数是怎么计算的呢?
首先,回顾下Transformer的注意力计算:
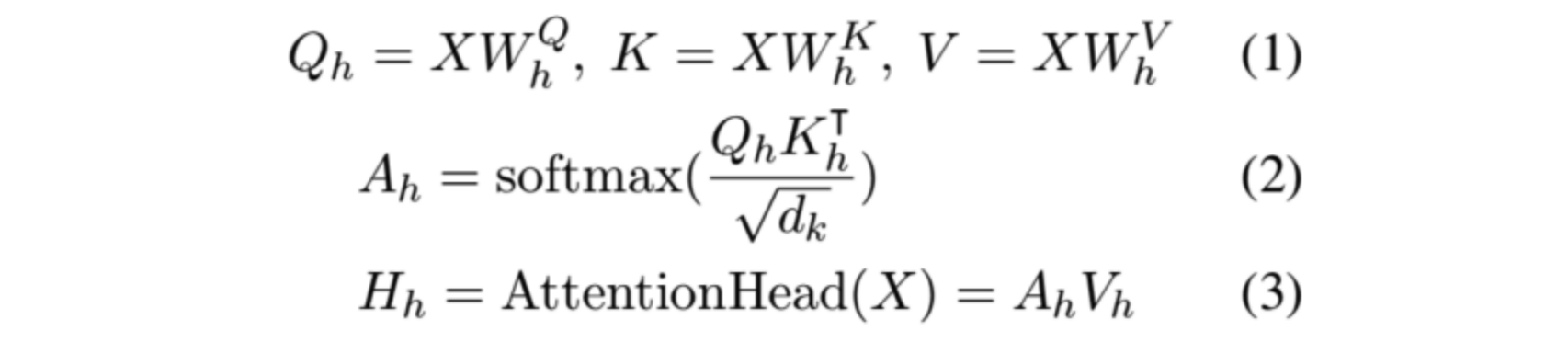
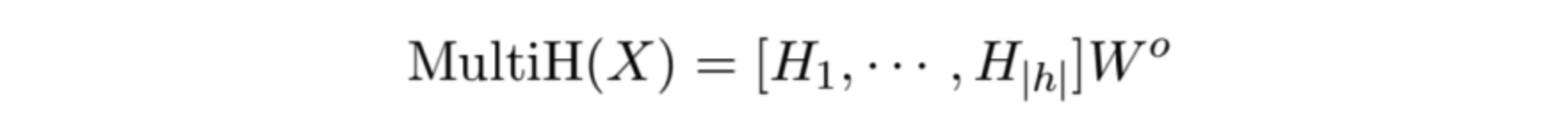
对于以上公式不熟悉的同学可以读下论文《attention is all you need》这里就不做介绍了。
之后,作者利用Transformer每个head的attention分数,去乘以该head的归因,就得到了归因分数矩阵,如下公式所示:

在这里,我们可以理解为归因是一个系数,乘以Ah矩阵后,就得到了该head的归因分数。那这个公式中的归因值是怎么来的呢?文章主要引用了《Axiomatic Attribution for Deep Network》的计算归因的方法。这篇计算归因的文章讲解可以看某呼文章《积分梯度:一种新颖的神经网络可视化方法》。这篇文章无论是从是从原理角度,还是从公式角度讲的都比较清楚,这里就不细讲了。
归因的具体计算就是将0-1的积分近似为平均来计算的,如下所示。相关的代码实现可以参考这里。
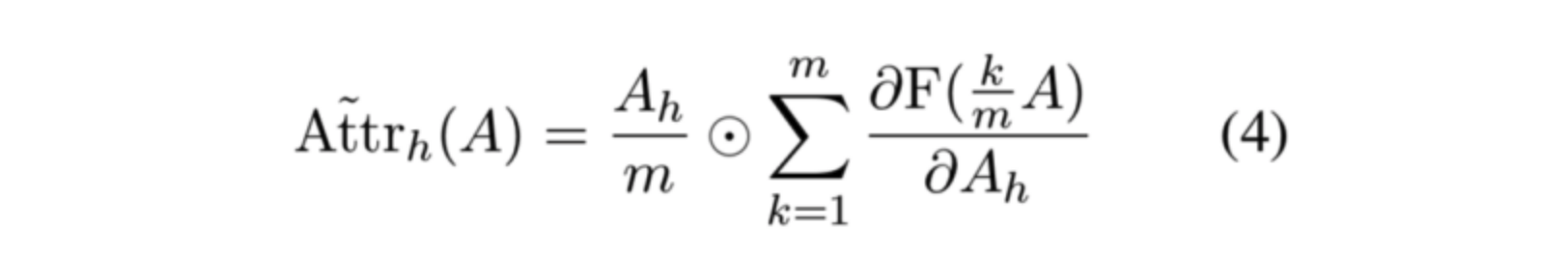
3.2、归因图
这部分主要是作者将归因分数具体到每个token并可视化的一个过程,而且平常我们也基本用不到这种方法,而且实现较复杂,但没什么具体技术含量,在此就不多做讲解,感兴趣的可以阅读原文。
3.3、head剪枝
这部分比较简单,其实就是利用归因分数的大小对head做了一个重要性排序,分数越高,重要性越大。论文中主要用了下面方法:
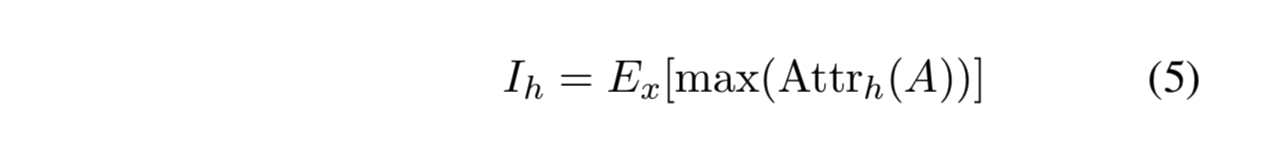
即取某个head的attention score矩阵中分数最大的值,然后在比较。E表示期望,x表示样本(验证集样本),就是说,从验证集中随机取一些数据,跑一遍,我们就可以得到在每条数据中每个head的归因最大分数,将每个head的这个分数求期望,然后排序。
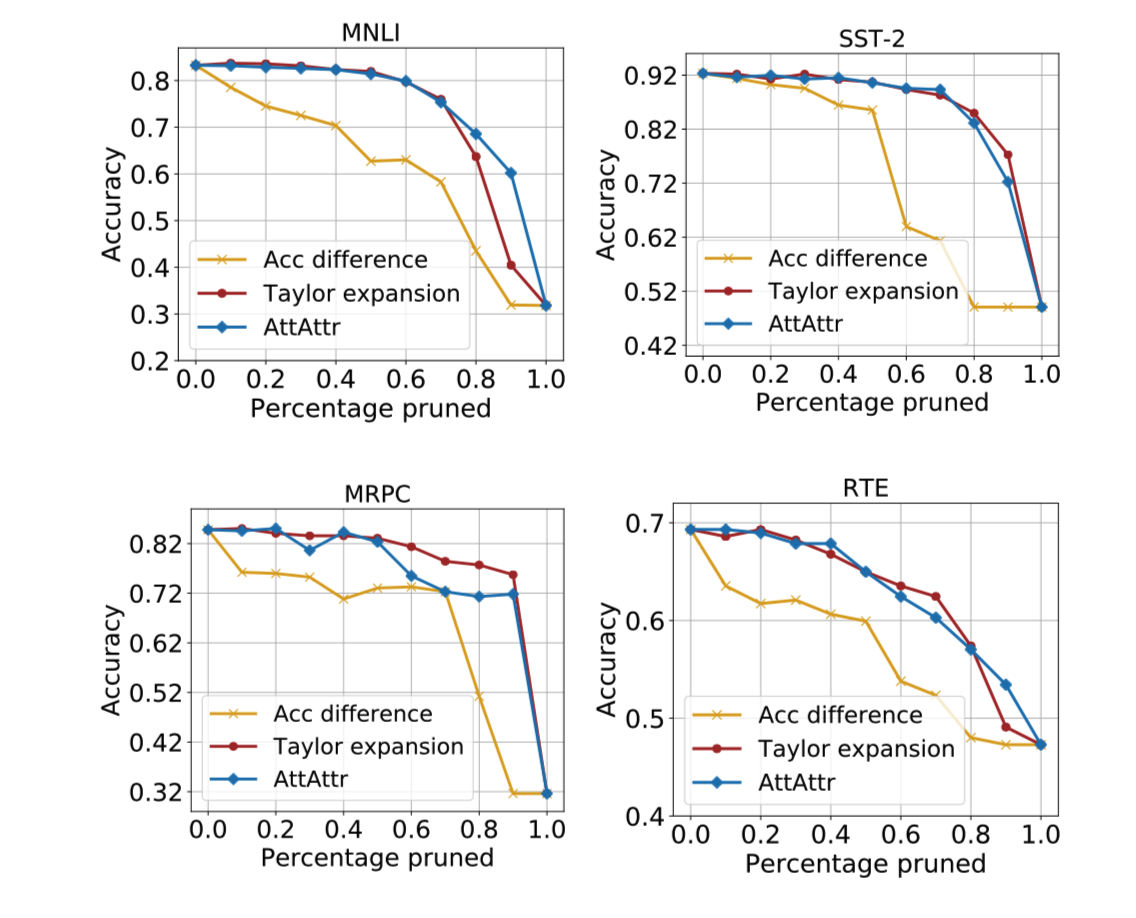
以下为在不同数据集上剪枝不同比例之后accuracy的结果对比。从结果可以看到,使用论文中的剪枝方法(蓝线),准确率衰减还是比较慢的。但本人认为,在工程实践时,大部分都不会裁剪过大比例(因为要保证准确率),所以相比Taylor expansion方法,几乎没什么区别。
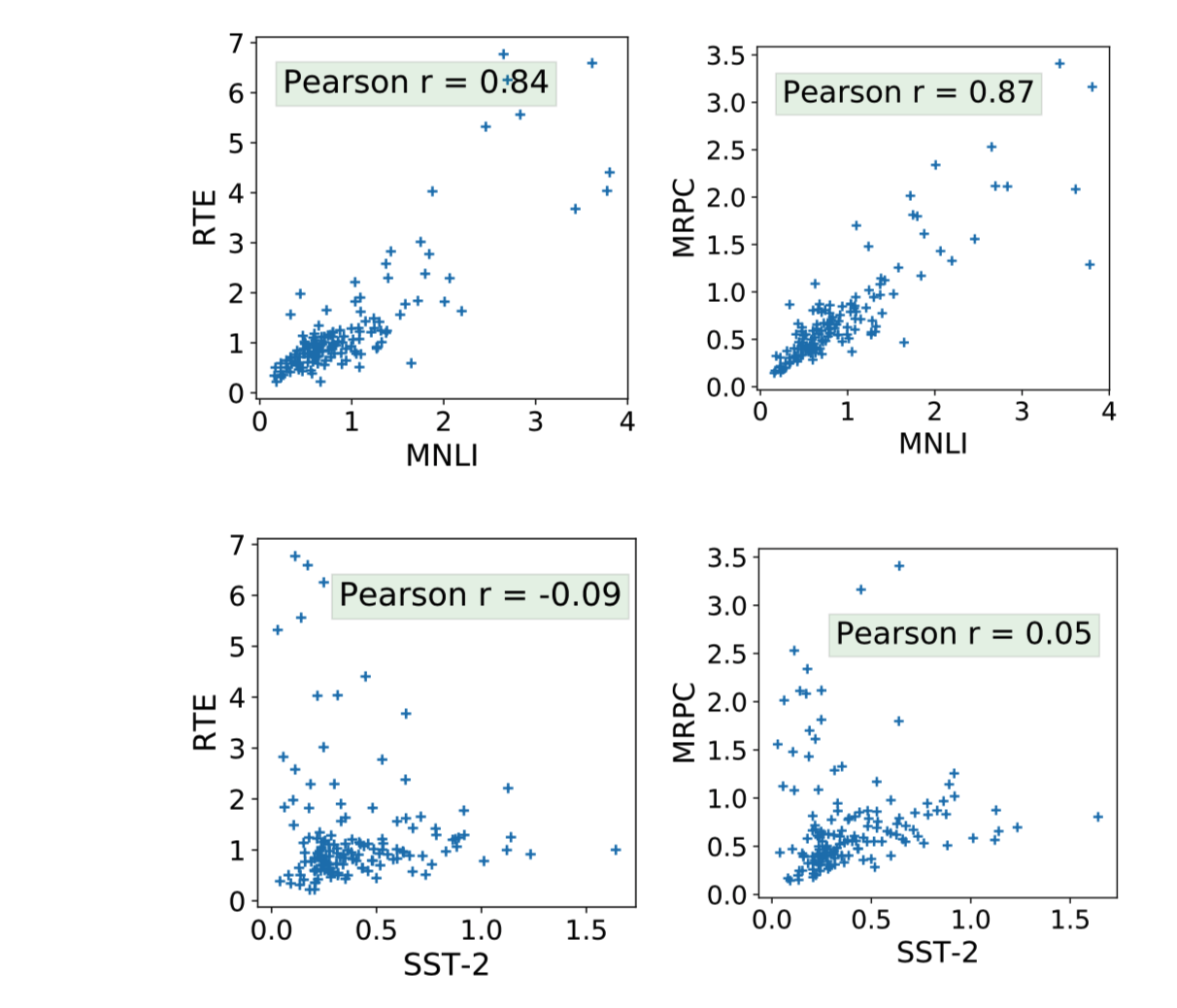
 之后,作者提出,head重要性分数和数据是否存在什么关系,比如同领域的数据head重要性排序是否一致,同类型任务的head重要性排序是否一致等等。因此,论文通过实验做了对比,如下所示。横纵坐标都表示head的归因分数,即不同数据集下head归因分数统计,Pearon r表示皮尔逊系数,越大表示越相关。从图中可以看到,RTE、MRPC和MNLI都具有很大的相关性,RTE、MRPC和SST-2相关性很低,RTE、MRPC和MNLI都是2句分类的任务,区别在于一个和MNLI是同领域,一个不同,而SST-2是单句分类任务。这说明,归因分数方法得到的head重要性只跟任务类型有关,和数据是否同领域无关。
之后,作者提出,head重要性分数和数据是否存在什么关系,比如同领域的数据head重要性排序是否一致,同类型任务的head重要性排序是否一致等等。因此,论文通过实验做了对比,如下所示。横纵坐标都表示head的归因分数,即不同数据集下head归因分数统计,Pearon r表示皮尔逊系数,越大表示越相关。从图中可以看到,RTE、MRPC和MNLI都具有很大的相关性,RTE、MRPC和SST-2相关性很低,RTE、MRPC和MNLI都是2句分类的任务,区别在于一个和MNLI是同领域,一个不同,而SST-2是单句分类任务。这说明,归因分数方法得到的head重要性只跟任务类型有关,和数据是否同领域无关。
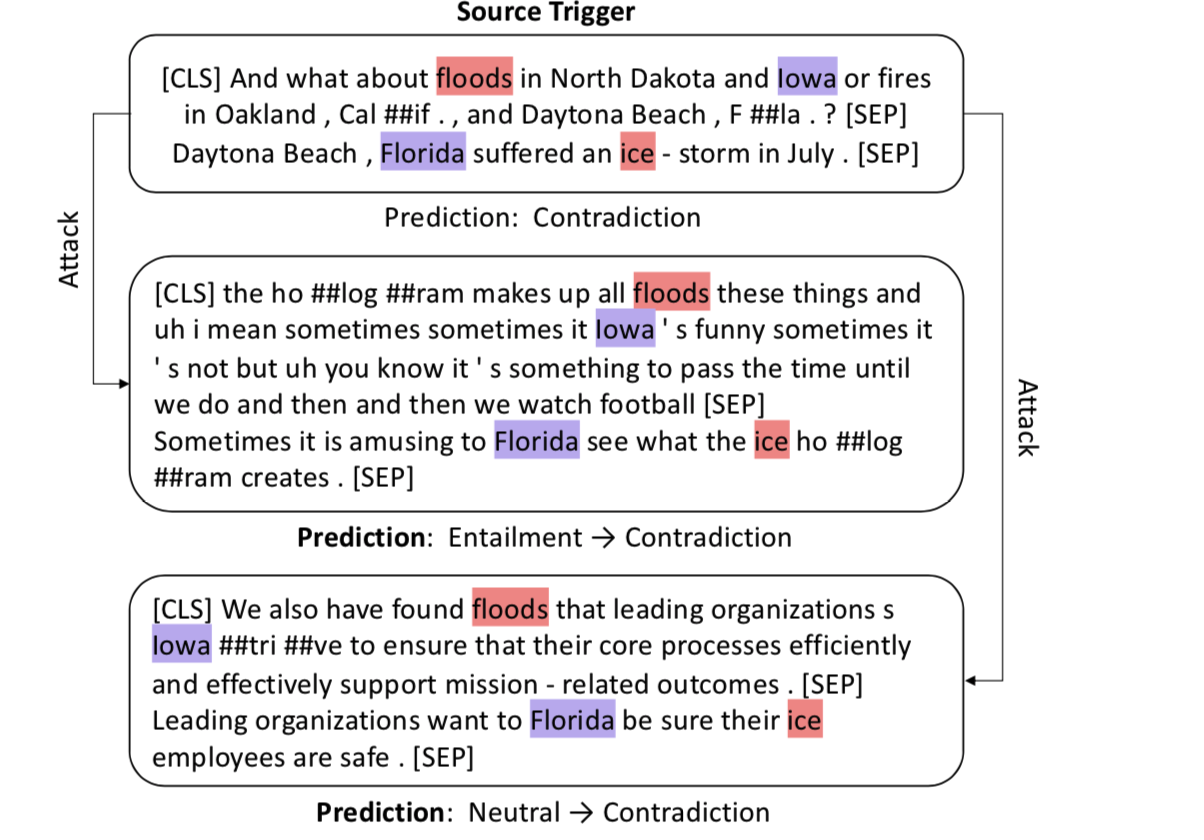
3.4、触发词攻击
利用归因分数topK的词(最大不超过5)去替换测试集句子中的某些词,注意,替换词之间的相对位置要类似。那么这个归因分数怎么具体到这个token的呢?文章并没有具体说明,但是在之前构造归因图的时候,通过公式,应该是根据token关注的分数之和计算的。
攻击的例子:
 攻击结果:
攻击结果:
 反正意思就是利用论文中归因分数得到的token替换到其他句子中,会极大的影响句子原本的分类标签。整体的准确率下降很多,比如MNLI的entailment标签准确率下降了80%。进一步证明了归因分数对于解释Transformer内部信息解释的合理性。
反正意思就是利用论文中归因分数得到的token替换到其他句子中,会极大的影响句子原本的分类标签。整体的准确率下降很多,比如MNLI的entailment标签准确率下降了80%。进一步证明了归因分数对于解释Transformer内部信息解释的合理性。
4、结论
提出了自我注意归因算法ATTATTR ,它解释了变压器内部的信息交互作用,使得自我注意机制更具解释性。然后利用分配得分推导出交互图,从而可视化变换器的信息流。对归因做了定量分析,以证明 ATTATTR 的有效性。在此基础上,利用所提出的方法对最重要的关注点进行识别,从而提出了一种新的关注点剪枝算法。最后,论文说明 ATTATTR 还可以用来构造对抗性触发器来实现非目标的攻击。在未来,可以应用这种方法来检查其他模型架构的信息交互,如 LSTM。
论文链接:《Self-Attention Attribution: Interpreting Information Interactions Inside Transformer》