1 摘要
ERNIE-GEN是采用多流序列的预训练和微调框架,通过生成机制和噪声感知生成方法来弥补训练和推理之间的差异。为了使代更接近人类的书写模式,该框架引入了一个跨越代流,训练模型连续预测语义完整跨度,而不是逐字预测。结果表明,ERNIE-GEN 在一系列语言生成任务中,包括生成式摘要(Gigaword 和 cnn / dailymail)、问题生成(SQuAD)、对话生成(Persona-Chat)和生成问题回答(CoQA) ,只需要很少的预训练训练数据和参数就可以获得最先进的结果。
2 拟解决问题
- 预训练和下游微调时的偏差问题;
- 解码时的错误累积问题;
- 生成的文本生硬问题。
3 创新之处
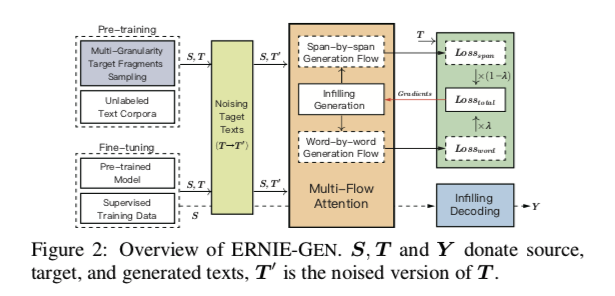
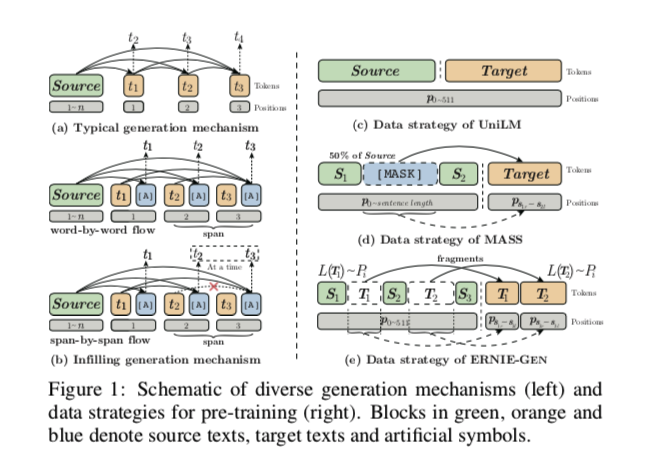
填充式生成。 在某一个位置插入人工符号[ ATTN ],[ ATTN ]能够在训练和推理的每个步骤中收集历史语境表征,从而将模型的注意力从最后一个词转移到所有以前的表征上,减轻以前错误对后续生成的负面影响,如图1(b)所示。
噪声感知生成。 通过随机替换词汇表中的任意词汇来破坏输入目标序列。 使模型能够意识到训练中的错误,以便模型能够发现错误,并在推理过程中消化它们。
word-by-word和span-by-span并行预训练。将一个跨越式的生成任务作为新一代流程引入到 ERNIE-GEN 中,以训练该模型来连续地预测语义完整的跨度,而不是像传统的 seq2seq 模型那样逐字逐句地预测。这项任务是通过填充生成机制与基于填充的逐字生成流程并行实现的,以促进预训练中的收敛,如图1b 所示。
3 架构
3.1 多粒度目标片段
给定一个源序列 S [ s1,... ,sn ] ,用概率 Pi 从一个分布集 p { P1,... ,Pl}中抽取一个长度分布 Pi,然后根据 Pi 迭代地选择各种片段,直到片段预算用完(例如 s 的25%)。 将 Sji表示为长度分布为 Pi的 第j个片段。 然后将取样的片段从 S 中移除并缝合在一起形成 目标句子序列T = { T1,... ,Tk} = { S1i,... ,Ski }。 在去除采样片段后,将 s ′表示为左源序列。ERNIE-GEN 通过预测分段目标序列 T 和最小化负对数概率来进行预训练:
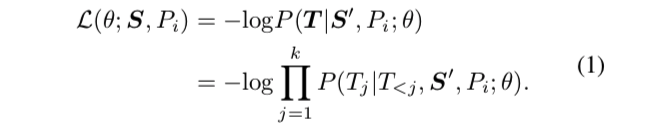
其中目标序列 T 按每个片段的位置排序,其中
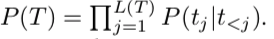
3.2 噪声感知生成器
用一个词被随机替换的过程来破坏真实序列 T,并将破坏的 T 表示为 T ′。 在预训练和微调过程中分别存在 pp 和 ff 两个超参数,分别表示噪声率。
3.3 架构: 多流注意力
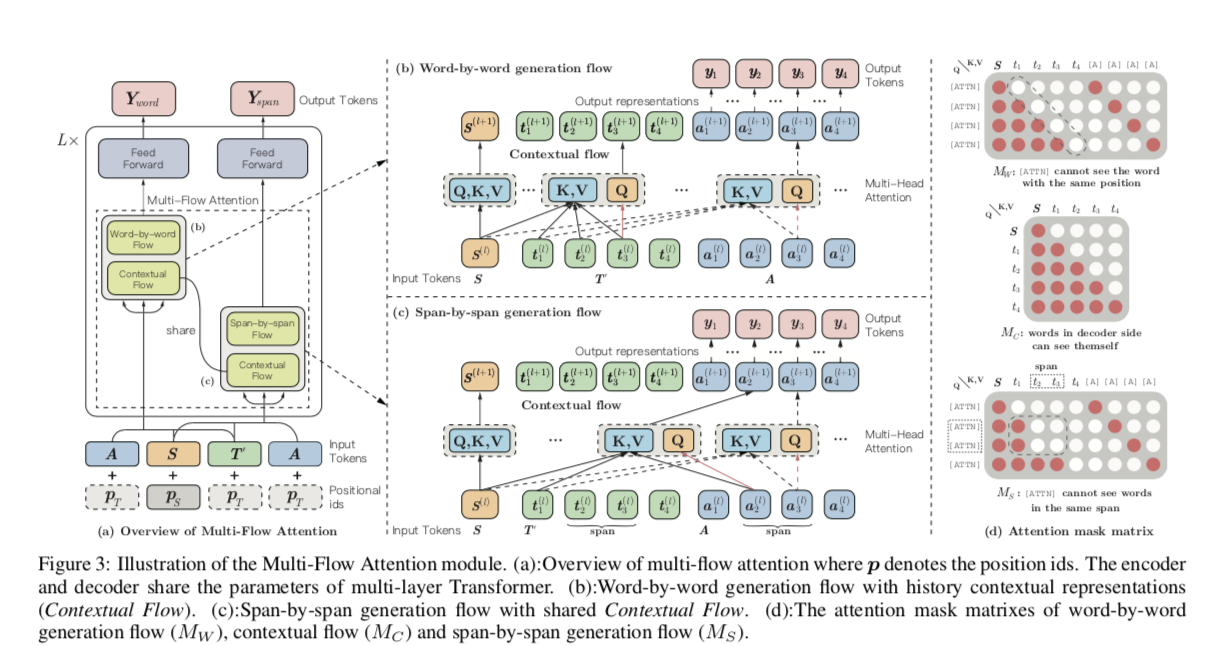 在形式上,给定源序列 S [ s1,... ,sn ] ,目标序列 T [ t1,... ,tm ]和与 T 长度相同的人工符号序列 A [[ ATTN ]1,... ,[ ATTN ]m ] ,我们按如下方式引入基于共享参数Transformer的 seq2seq 网络:
在形式上,给定源序列 S [ s1,... ,sn ] ,目标序列 T [ t1,... ,tm ]和与 T 长度相同的人工符号序列 A [[ ATTN ]1,... ,[ ATTN ]m ] ,我们按如下方式引入基于共享参数Transformer的 seq2seq 网络:
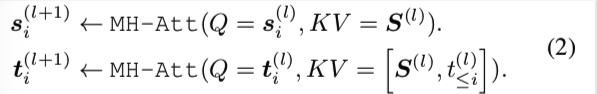 其中 q,k,v 表示在多头注意操作中的查询、键和值[ Vaswani et al. ,2017]。 si(l)和ti(l)表示encoder和decoder第 l 层的第i个token向量表示。对编码器和解码器分别采用多头注意,[.]表示拼接运算。 在这项工作中,我们将上述过程称为上下文流。
其中 q,k,v 表示在多头注意操作中的查询、键和值[ Vaswani et al. ,2017]。 si(l)和ti(l)表示encoder和decoder第 l 层的第i个token向量表示。对编码器和解码器分别采用多头注意,[.]表示拼接运算。 在这项工作中,我们将上述过程称为上下文流。
逐字生成流程:基于填充生成机制,这个流程使用了一个插入的[ ATTN ]
符号逐字收集历史表示(见图1b)。
 其中对于插入的符号序列A, a il表示 l层的第i个token向量表示
其中对于插入的符号序列A, a il表示 l层的第i个token向量表示
逐段生成流: 与逐字生成流不同的是,逐段流使用[ ATTN ]连续预测完整跨度,如图3c 所示。 在形式上,给定一个跨度边界列表 B = [b1,... ,bk] ,按以下方式进行逐段生成流:
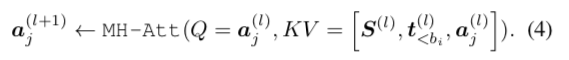 其中 j ∈[ bi,bi+1] ,aj(l)表示第i片段的第(j-bi) 向量表示。
其中 j ∈[ bi,bi+1] ,aj(l)表示第i片段的第(j-bi) 向量表示。
本质上,该模型被训练为在相同的历史上下文[S,tbi] 下预测整个跨度 tbi: bi+1。 与随机抽样范围相反,我们更喜欢包含语义信息和知识的抽样片段。 特别地,我们考虑以下两个步骤连续在 T中取样跨度:
- 首先,我们使用 T-test来计算所有的二元和三元 t-statistic分数。这个计算基于一个假设H0:随机跨度的n个随机单词W = [w1,... ,wn]的概率为:
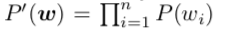
不能是一个统计 n-gram。 T-statistic分数由
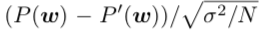
计算,其中 p (w)表示统计概率和标准差σ,而 N 则表示在训练数据中出现的 n-gram。根据T-statistic分数,我们过滤出前200,000个bigrams,前50,000个trigrams和所有的 unigrams 来构建一个特定的跨度词汇,这就是 Vspan。
- 其次,我们按顺序搜索 trigram、 bigram 和 unigram,从当前单词开始,直到在Vspan检索到一个 span (n-gram,n ≤3)。
多流注意力:逐字生成流 + 跨度生成流,共享上下文流,如图3a 所示。 多流注意力计算如下:
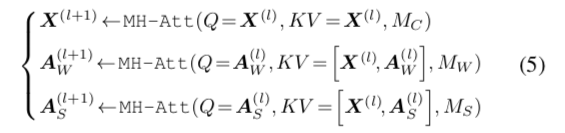 其中 X 表示 S 和 T ′的拼接,AW,AS 是分别输入到逐段生成流和跨越生成流的人工符号序列。 如图3d 所示,注意力遮掩矩阵 M 通过修改注意力权重 W = softmax (QKT/ √ dk + M)来确定query和key是否可以相互关注[ Vaswani et al. 2017]。 M为:
其中 X 表示 S 和 T ′的拼接,AW,AS 是分别输入到逐段生成流和跨越生成流的人工符号序列。 如图3d 所示,注意力遮掩矩阵 M 通过修改注意力权重 W = softmax (QKT/ √ dk + M)来确定query和key是否可以相互关注[ Vaswani et al. 2017]。 M为:

在训练过程中,加入了逐字生成流和逐段生成流的损失,并用一个系数:

其中 Yword 和 span 表示生成的两个序数,L (.)表示交叉熵损失函数。 预训练和微调中 λ 分别设置了0.5和1.0。
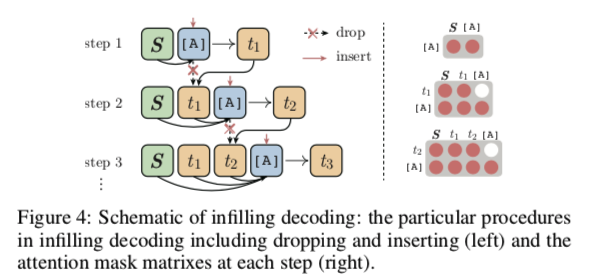
3.4 填充解码
在解码过程中,由于目标序列 T 是未知的,因此不需要事先准备一个人工的符号序列 A,而是逐步插入[ ATTN ]来收集历史上下文的表示。 同时,为了提高效率,需要在每个步骤的推断之后删除所插入的[ ATTN ] ,如图4所示。
4 微调下游工作
生成式摘要的目的是生成流畅、简洁的摘要,而不需要从输入文章中抽取子序列。
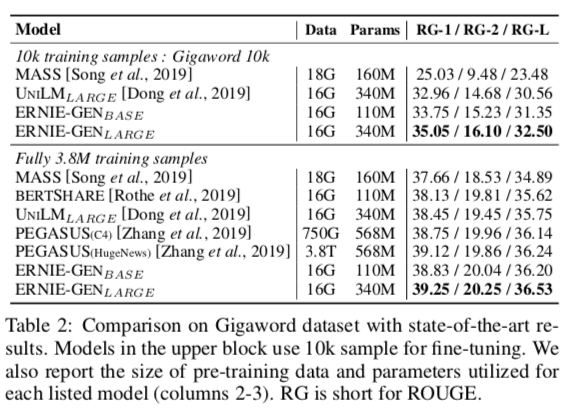
表2显示了 Gigaword的10K 和3.8M数据的结果,表1为微调设置。 在低资源任务(Gigaword 10k)中,ERNIE-GENBASE 比 UNILMLARGE 在 ROUGE-L 中增加了 + 0.79个点,而 ERNIE-GENLARGE 比 UNILMLARGE增加了 + 1.94个 ROUGE-L。 在完整的 Gigaword 数据集上,ERNIE-GENLARGE 创建了最先进的结果,超越了各种各样的方法。
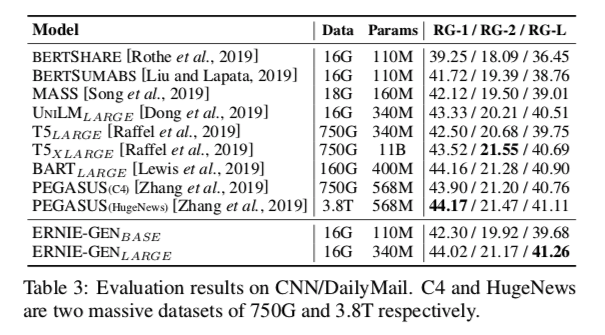
表3显示了 CNN / DailyMail 上的性能。 对于类似数量的训练前数据和参数,ERNIE-GENBASE 比 MASS 的 ROUGE-L 分数高出0.67分。 与 UNILMLARGE相比,ERNIE-GENLARGE获得了 + 0.73的 ROUGE-L 分数。 同时,尽管前期训练的数据和参数很少,我们的大型模型 ERNIE-GENLARGE在 ROUGE-L 上也取得了最先进的结果,在 ROUGE-1和 ROUGE-2上也取得了可比的性能。
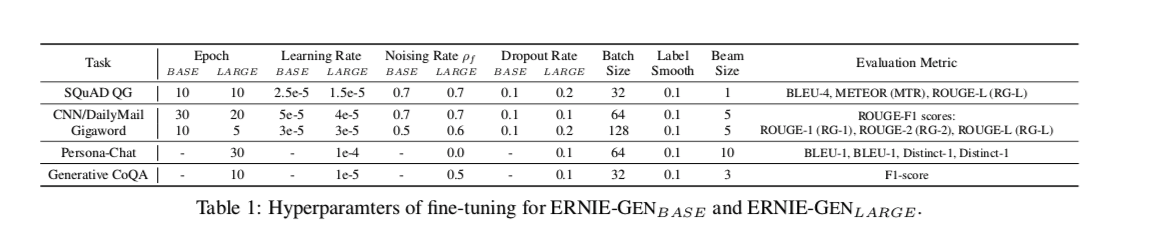
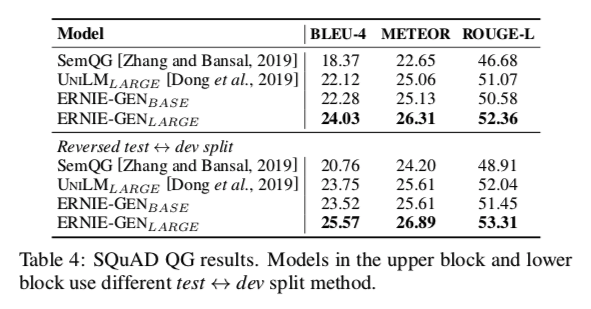
问题生成任务(称为SQuAD QG) :反向开发<-->测试分裂的实验指输入源序列是输入段落和答案文本的连接,而目标序列是一个给定的问题。 ERNIE-GEN优于UNILM,取得了最好的分数。(表4)
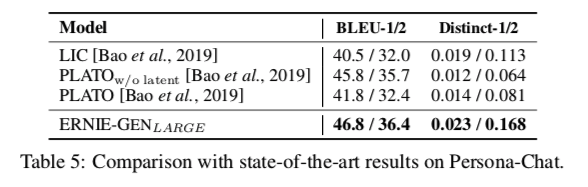
对话生成(Persona-Chat)表示根据之前的句子生成下一句对话。ERNIE-GEN在该数据计算取得sota。(表5)
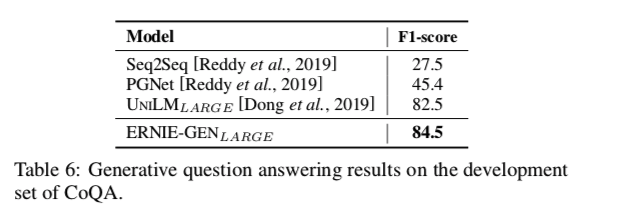
生成性问题回答/多轮会(CoQA)话:表5显示,ERNIE-GEN 在生成对话方面优于目前的特定任务的预训练模型。还在 CoQA 数据集上做了一个实验,为输入的问题和对话生成自由格式的答案,ERNIE-GEN模型比f1分数比早期模型要更高(表6)。
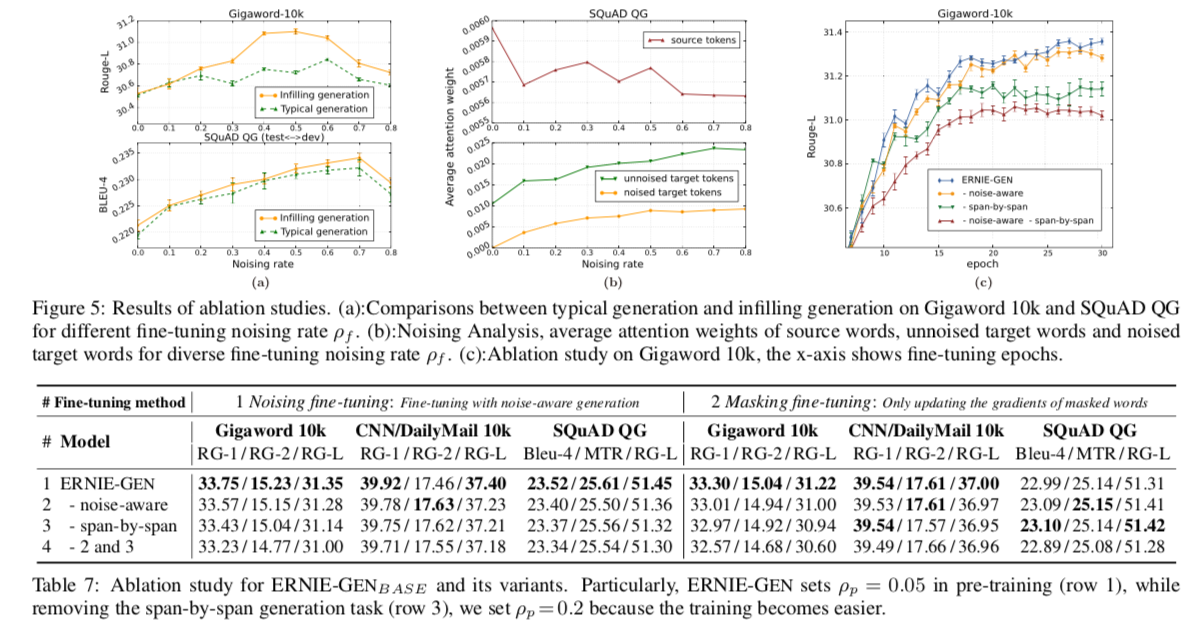
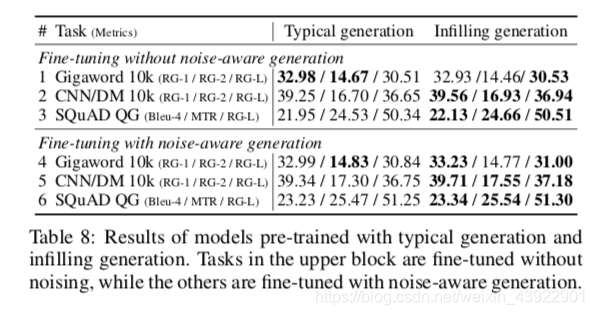
5 消融研究
为了更好地理解每种生成方法的重要性,进行了以下两个方面的实验进行消融对比:
针对下游任务的偏差,填充生成机制及噪声感知生成方法的稳健性。
逐段生成任务的有效性和完整的 ERNIE-GEN 模型。
5 结论
提出了一个用于语言生成的增强型多流 seq2seq 预训练和微调框架(ERNIE-GEN) ,其中包括一个填充式生成机制和一个噪声感知生成方法,以减轻预训练和微调的偏差。 此外,ERNIE-GEN 还集成了一个新的跨度生成任务来训练该模型生成类似人类书写的文本,进一步提高了下游任务的性能。ERNIE-GEN 在一系列的 NLG 任务中实现了最先进的结果。