by 方祖亮
1 引言
神经网络的本质是连接,通过加深网络层数,能逐渐扩大信息捕获范围(感受野),最终实现全局信息的有效整合和加工。
1.1 卷积的两个问题
1.1.1 感受野不够
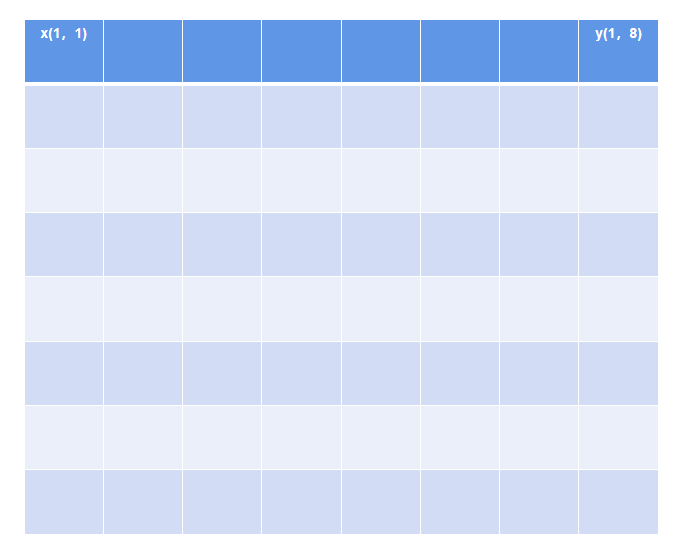
在Attention机制提出来之前,主流的扩大感受野的方法是卷积Conv和池化Pool操作(本质上池化也是卷积的一种). 从获取全局信息角度来看,Conv是一种比较低效的操作。以一张8*8的图片为例,x(1,1)的信息要和y(1,8)处的信息发生交互的话,假设卷积核大小为(3,3),stride为1,则需要做(8-3+1)/stride = 6次卷积。而一般工业场景中图片宽、高度都在200以上,即使加大卷积核和滑动步长,仍然需要很深很深的网络才能整合全局信息。ImageNet比赛的历年冠军模型如ALexNet、VGGNet、Inception Net、ResNetResnet都有很深的卷积层。
目前工业实践中一些不太深的网络如果也能取得不错的效果,是因为在大部分任务中,全局信息不是必须的。这与人的生活很类似:被领域内80%的人所熟知就已经算获得成功了。卷积操作是一定程度上是符合人的认知的,即周边信息比远距离信息更有价值。
1.1.2 权重固定
针对第一个问题,我们很容易想到:用全连接FCN不就可以轻易感知全局信息吗?的确全连接可以解决这个问题,但只是解决了部分问题,并带来了计算灾难。
计算灾难
首先说计算灾难
假设我们有一个100*100的输入,使用全连接展开,则第一层为100 *100 = 10000个节点,假设全连接尺寸不变,第二层也为100 * 100 = 10000个节点,则参数量为 10000 * 10000 = 1 * 10e8
如果使用卷积,kernel_size = (5,5), stride = 2, 需要(100 - 5 + 1)/ 2 = 48次卷积能整合全局信息,假设每次卷积的输入输出通道都为32,则参数量为:32 * 32 * 5 * 5 * 48 = 1.2288 * 10e6。
前者相比后者多了两个量级的参数。
权重固定问题
- 无论是全连接还是普通卷积,如果技巧得当,我们有理由相信该模型在新的数据集上是具有很强的泛化能力的。但是此时的模型参数都是固定的,即无论输入什么,在模型的指定位置上,该参数都是一致的,与输入无关。
由此提出几个问题:
模型的参数权重能不能合理反映空间或者时间上位置之间的依赖关系?
这种依赖关系是否能够适用在任何输入上?
能否根据输入自适应的去表征这种位置之间的依赖关系?
1.2 Attention原理
Attention的横空出世,成功地解决了上述多个问题。
Attention是通过对全局feature_map做自相关,能有效整合全局信息,这点在下文会有补充。
Attention通过能构建与输入相关的位置之间的依赖关系,即哪些局部特征与问题最相关,分配到的权重越多。将有限的注意力集中在重点信息上,快速获得最有效的信息。
Attention的权重参数不是固定的,针对不同的输入能自适应构建权重分配关系,千人千面。
对比全连接和Attention:
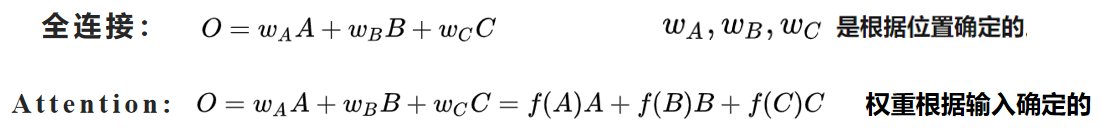
打个不恰当的比喻:
卷积就是一个勤勤勉勉的高中学子,只有通过平时用功努力,才可能在高考考场上得到不错的成绩,但是也有可能遇到一些生僻的题型。
Attention就是一个运气和努力共存的学生,不仅平时基础打得好,考场考的东西还都是自己会的。
近几年Attention机制在计算机视觉和自然语言处理领域都取得了重要的突破,对模型性能提高有较大帮助。下面通过讲述一些计算机视觉上常用的Attention机制及其原理,来探究Attention本质。
2 Attention分类
视觉Attention根据其实现方式主要分为两类:空间注意力和通道注意力。假设输入的feature_map: X = [channel, height, width]
2.1 通道注意力
step1:对输入的X进行F(X) 映射. 常见的映射过程包括对每个channel的[height, width]进行Pool操作、或者卷积操作等。
得到 Atten = F(X); 其size = [channel, 1, 1] .
step2: softmax或者sigmoid 进行[0,1]化 . 得到weight = sigmoid(Atten) ,size = [channel, 1,1].
step3: 给每个通道上的信号乘上对应的权重。最终输出为:Y = X * weight. size = [channel, height,width]
eg: Y[i, :, : ] = X[i, :, ;] * weight[i] .
2.2 空间注意力
step1: 对输入的X进行F(X) 映射. 常见的映射过程包括对所有channel的[height, width]进行sum、mean或者卷积操作等。
得到 Atten = F(X); 其size = [1, height, width].
step2: softmax或者sigmoid 进行[0,1]化 . 得到weight = softmax(Atten) ,size = [1, height,width].
step3: 对所有通道上所有对应的空间信号乘上对应的权重。最终输出: Y = X * weight, size = [channel, height, width]
eg: Y[:,i, j] = X[:, i, j] * weight[:, i, j]
相比来说,通道注意力参数量比空间注意力少,建议空间注意力和通道注意力搭配使用。下面将按时间线介绍一些比较知名的视觉Attention网络,并附上pytorch版本代码。
https://github.com/fangzuliang/Meteorology_FZL/tree/master/CV_Attention
3 传统视觉Attention网络
3.1 2017: SENet - 通道注意力
- SENet:Squeeze-and-Excitation Networks
论文地址:https://arxiv.org/abs/1709.01507
代码地址:https://github.com/hujie-frank/SENet
谈到视觉注意力,SENet是不能绕过的一座大山,后续很多的Attention文章都是在SENet的基础上做的魔改。
SENet是Squeeze-and-Excitation Networks的简称,由Momenta公司所作并发于2017CVPR, SENet赢得了ImageNet最后一届(ImageNet 2017)的图像识别冠军.
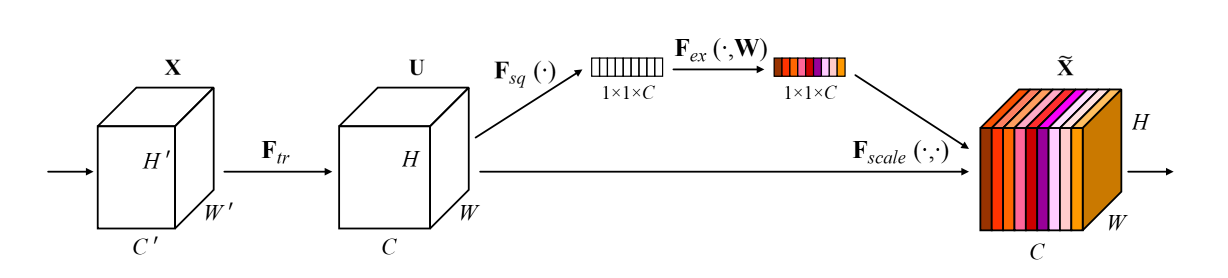
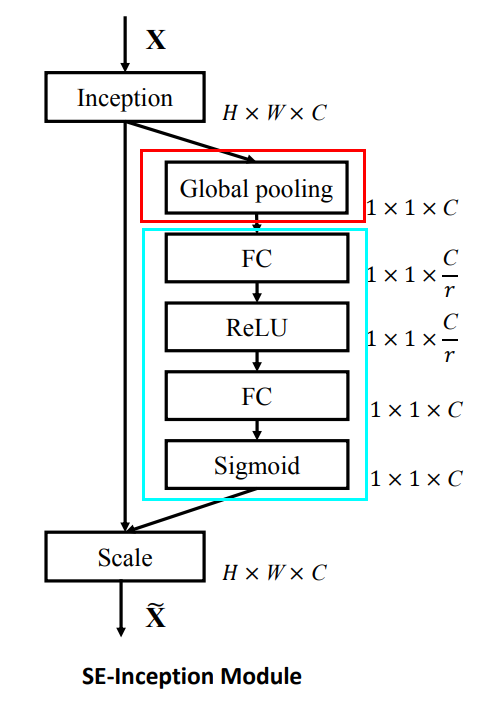 - 亮点:SENet就是典型的通道注意力机制。其中Global pooling部分就是Squeeze,获取全局感受野,青色方框的FC全局连接和非线性变换就是Excitation过程,显式构建特征通道的相关性。通过控制scale的大小,把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强。
- 宋宽博士的文章《Deep Learning Prediction of Incoming Rainfalls: An Operational Service for the City of Beijing China》雷达外推模块就用到了这个SENet.
- 亮点:SENet就是典型的通道注意力机制。其中Global pooling部分就是Squeeze,获取全局感受野,青色方框的FC全局连接和非线性变换就是Excitation过程,显式构建特征通道的相关性。通过控制scale的大小,把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强。
- 宋宽博士的文章《Deep Learning Prediction of Incoming Rainfalls: An Operational Service for the City of Beijing China》雷达外推模块就用到了这个SENet.
3.2 2018: CBAM - 通道 + 空间注意力
CBAM:Convolutional Block Attention Module(CBAM)
论文地址:https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf
图示
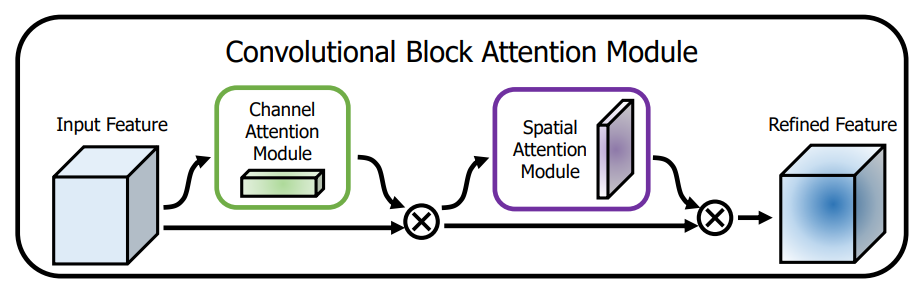
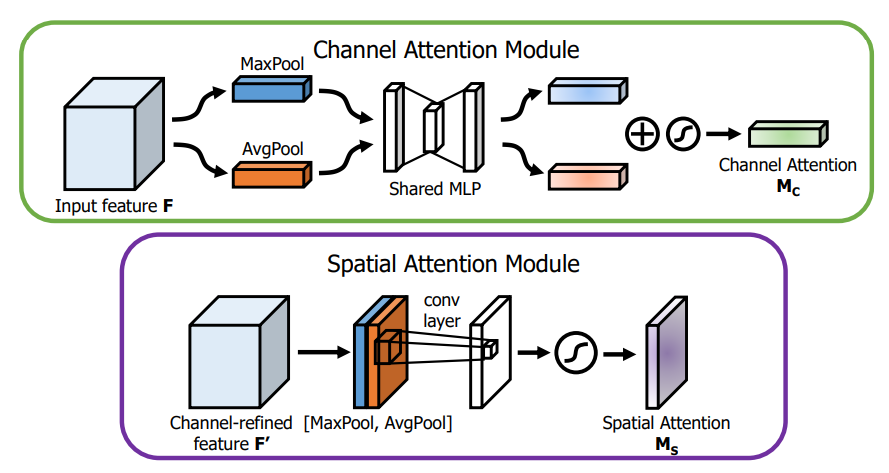
亮点:
- 通道注意力模块的Squeeze部分同时叠加了MaxPool 和 MeanPool操作,高阶信息变得丰富。
- 同时串联了空间注意力,空间注意力的实现也用到了Maxpool和MeanPool,concate后接卷积。
- 应该会比单独使用SENet效果好。
3.3 2019: SKENet - 通道注意力
SKENet: Selective Kernel Networks
论文地址:https://arxiv.org/abs/1903.06586
代码地址:https://github.com/implus/SKNet
Selective Kernel Networks(SKNet)发表在CVPR 2019,是对Momenta发表于CVPR 2018上论文SENet的改进,且这篇的作者中也有Momenta的同学参与。SENet是对特征图的通道注意力机制的研究,之前的CBAM提到了对特征图空间注意力机制的研究。这里SKNet针对卷积核的注意力机制研究。
图示
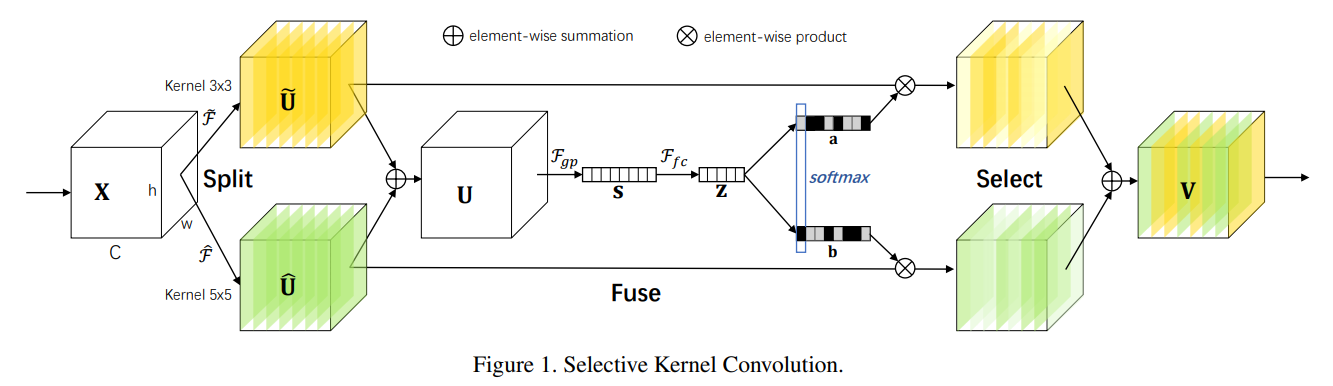
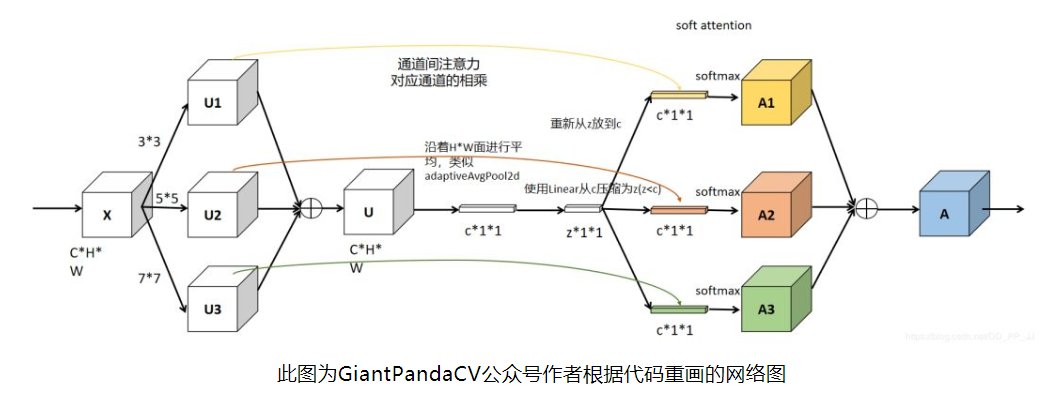
SKENet看上去比较复杂,但是其本质上就是Inception结构和多个SENet的结合。
- 亮点:
- SENet只考虑对输入的featuremap:X做通道卷积,featuremap的信息是固定单一的。
- split: SKENet先对输入的feature_map X使用不同大小的卷积核进行卷积操作,得到多个(n个)特征图。
- fuse: 将多个特征图相加,信息更加丰富。之后使用SENet的思想进行Squeeze 和 Excitation,
- select: Excitation阶段使用n个线形层得到n个size = [channel,1,1]的通道权重,分别作用在split后的n个特征图上,之后相加,输出Y。
3.4 2020: ECANet - 通道注意力
#ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
#论文地址: https://arxiv.org/abs/1910.03151
#代码地址:https://github.com/BangguWu/ECANet
- 图示
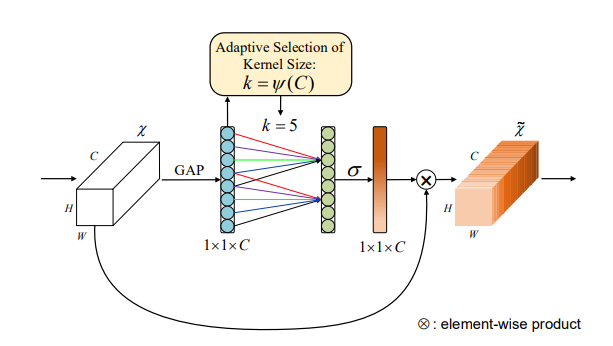
亮点: ECANet主要是对SENet模块进行了一些改进。
- SENet的通道之间的信息交汇是通过linear实现的,存在一个 C --> C/r --> C ,即降维和升维的操作。ECANet是通过对通道C进行1维卷积从而实现通道间的信息交互,这个过程没有发生降维。作者的经验表明避免降维对于学习通道注意力非常重要,适当的跨信道交互可以在显著降低模型复杂度的同时保持性能。
- 卷积核大小的选取是自适应的,与通道数C成正比,呈log关系。
计算机视觉发展到现在,2020年还能使用改进的SENet中了CVPR, 说明该轻量级网络模块的确有奇效,后续可以实践实践。
3.5 2020: RecoNet - 通道 + 双空间注意力
3.5.1 图示及其原理
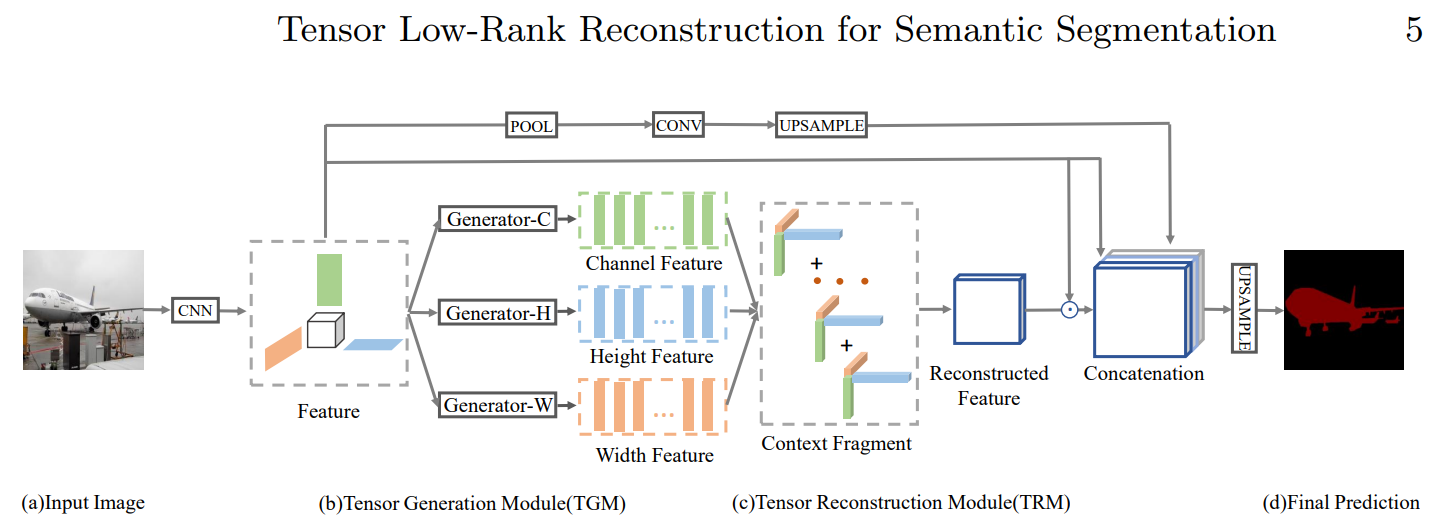
- RecoNet主要由2个模块组成:张量生成模块TGM 和张量生成模块TRM组成。
- TGM模块。主要思路:分别对输入的特征图X = (channel, height, width) 的通道、空间H 、空间W进行某种映射(全局平均池化、卷积、sigmoid)得到对应的低阶张量Ci = C×1×1,Hi = 1×H×1 Wi = 1×1×W,重复上述过程r次,即得到r个 Ci,Hi,Wi。r=64时表现最好。
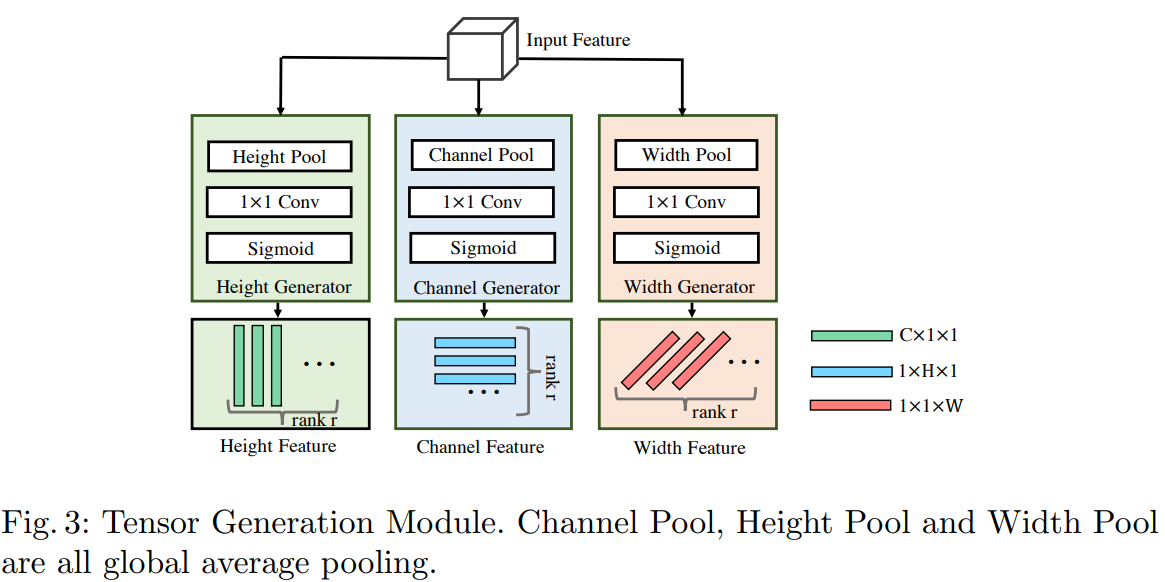
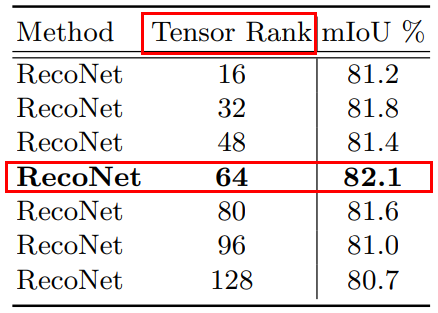
- TRM模块。 根据TGM模型生成的r个 低阶张量,依次生成对应的r个Ai,即Ai = Ci * Hi * Wi , size = (C, H, W).
最终得到
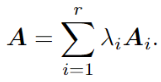 即为重构的全局信息,其中λi是可学习的参数。
即为重构的全局信息,其中λi是可学习的参数。
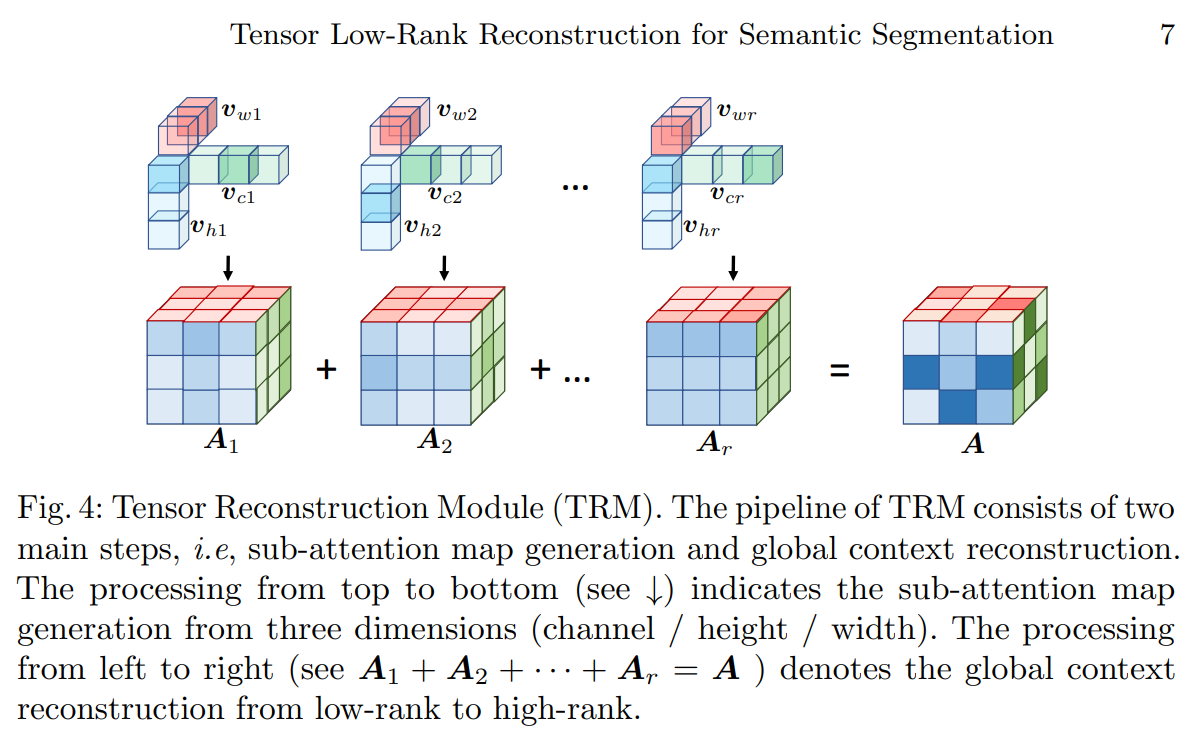
- 最终输出: Y = concatenate([A * X ,F(X)] ,axis = 1), 即在通道维度上进行拼接, 其中F(X) 为Pool + Conv + Upsample。
3.5.2 亮点
- 这里通道注意力的实现和ECANet差不多,全局池化 + Conv + Sigmoid,不同处在于ECANet是Conv1, 对通道做卷积,而这里的使用1*1卷积核对空间二维卷积。
- 双空间注意力:之前的CBAM也是通道注意力+空间注意力,但其空间注意力的计算是[H,W]对应位置上的所有通道值的映射,信息维度较低。后面的self-attention中的空间注意力和Non-local可以避免这个问题,但是计算量是比较大的。而RecoNet是对[C, H, W]的每个axis 都采取类似之前的通道注意力的计算方式,既可以由高维信息计算权重,计算量也较小(相比Non-local计算量少了2个量级),普适性和可迁移性较强。
- 张量正则-多态分解理论(即高阶张量可以表示为1级张量的组合)思路对后续模型设计也有较大启发,之前遇到的问题—捕捉越高级的特征,需要的参数和张量维度越大,或许有更轻便的设计。
4 Self-Attention
之所以称SENet\CBAM\SKENet\ECANet为传统的Attention机制,是因为其设计理论中无论是通道还是空间注意力,在对自身做映射时,F(x)都有限的、简单的Pool 或者线性层,参数量不多。而自从《Attention is All you need》发表后,Self-Attention便成为了炙手可热、风光无限的注意力机制,在NLP领域掀起新一轮发展浪潮,而CV领域的Attention 机制也受其影响,有了很多改造版。
Self-Attention中的亮点将自身映射为三个分支向量: Query,Key,Value ,即得到自身信息的多个表达。后续操作通常分为三步(以计CV中的self-attention为例):
- Step1: 计算权重:将Query 和每个Key 进行相似度度量(点积)得到权重W;
- Step2: 归一化: 使用softmax(W)得到归一化后的权重;
- Step3: 加权求和:将权重和对应位置的Value进行加权求和,得到attention;
- 一般对特征图X进行self-attention后,也会进行一个残差连接,即:Y = X + self_attention(X)
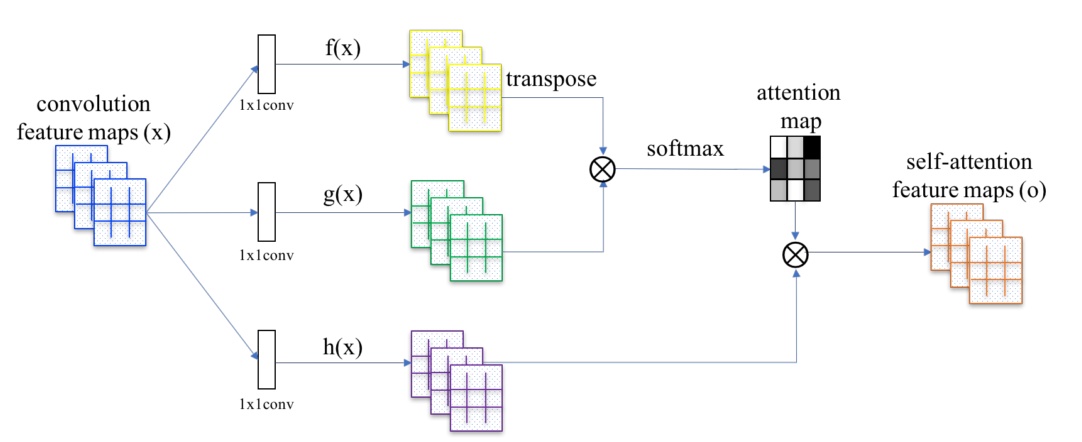 一般提起self-attention默认指空间注意力,按照self-attention的原理也可以实现通道注意力.代码会后期统一给出。
一般提起self-attention默认指空间注意力,按照self-attention的原理也可以实现通道注意力.代码会后期统一给出。
4.3 2018: Non-local - 空间注意力
#论文地址:https://arxiv.org/abs/1711.07971
#代码地址:https://github.com/pprp/SimpleCVReproduction/tree/master/attention/Non-local/Non-Local_pytorch_0.4.1_to_1.1.0/lib
《Non-local Neural Networks》是计算机视觉领域非常基础的一篇文章,为了有效捕捉长距离特征之间的依赖关系,提出了非局部信息统计的Self-Attention。非局部操作直接计算两个位置(可以是时间位置、空间位置和时空位置)之间的关系即可快速捕获长范围依赖,但是会忽略其欧式距离,这种计算方法其实就是求自相关矩阵,只不过是泛化的自相关矩阵;
- 图示
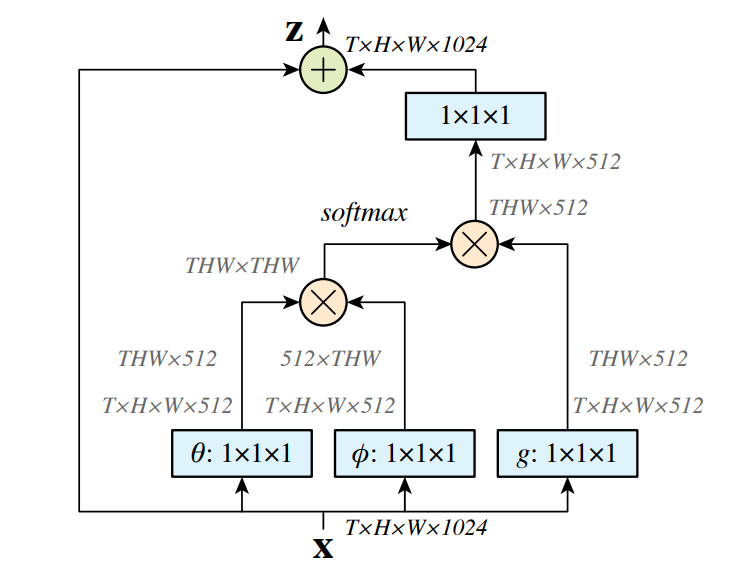
- 亮点:通过自身的多个表示之间的相似关系获取全局的重要依赖。图示中的θ,φ,g其实就类似于self-attention中的Query,Key, Value. 不同之处在于输入之前做了个1*1卷积降低通道数。
- 应用:眼控科技在做台风风速定量分析时,就使用了这个Non-local。
4.4 2019: DANet - 通道 + 空间注意力
#《Dual Attention Network for Scene Segmentation》
#论文地址 https://arxiv.org/pdf/1809.02983.pdf
#github地址:https://github.com/junfu1115/DANet/
4.4.1 原理
- DANet 是空间注意力 + 通道注意力的并联集成,都是采用的self-Attention机制。
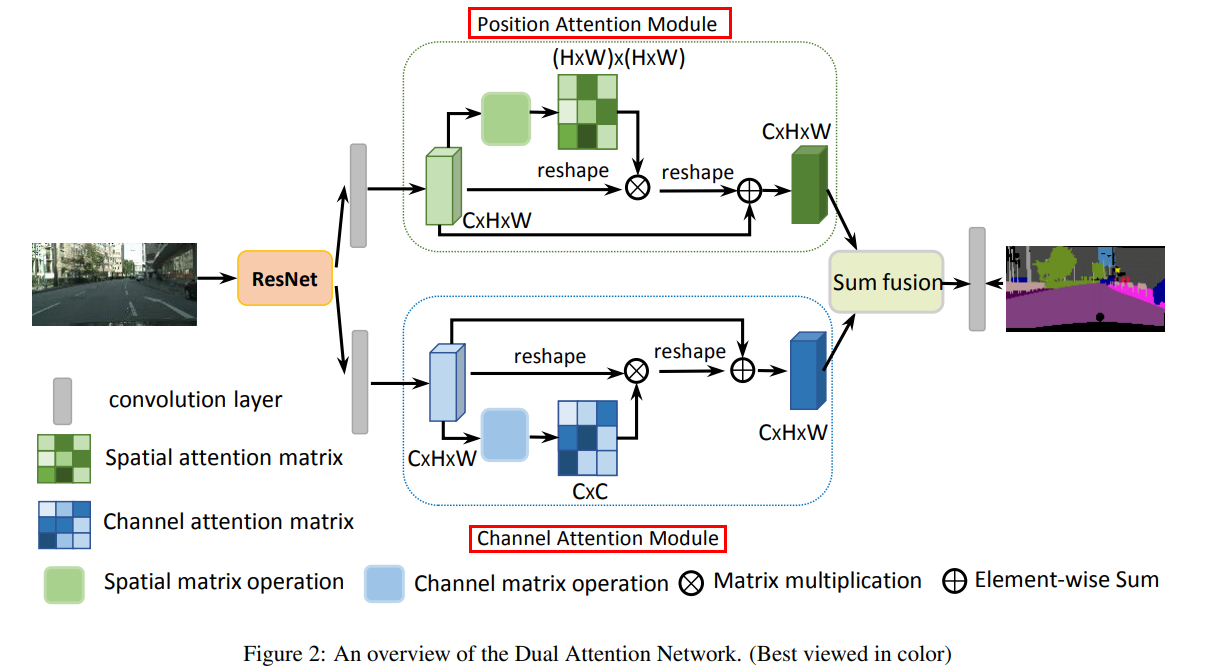
- Position Attention module: 思路和 4.1节中的空间self-attention思路一致,即先将特征图A通过卷积操作映射为 3个特征图:Query(B) 、Key(C) 和Value(D),之后通过F(Q, K)获取空间权重,作用在Value上,再加上残差连接,得到最后的输出。
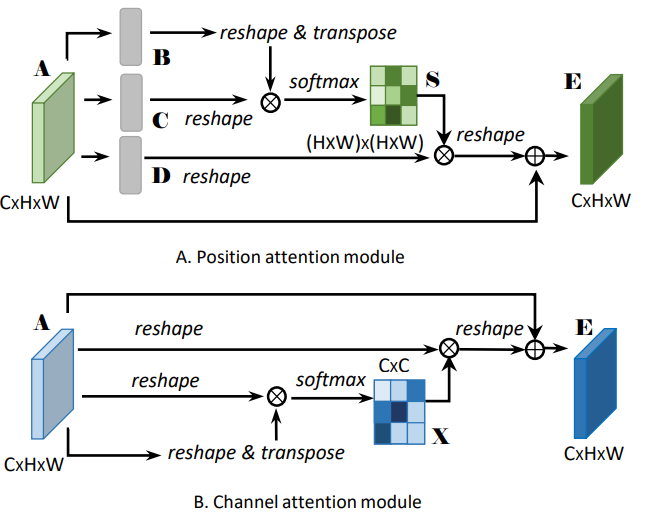
- Channel Attention module: 不同于4.2节中的通道注意力的self-attention实现,这里在将特征图X映射为 Q、K和V三个向量时,没用使用卷积,而是简单的Reshape操作,作者认为这样可以有助于维持不同通道特征图之间的关系。个人认为这一点有待商榷。
5 轻量级Self-Attention
Non-Local能力强大,但是需要占用很多计算资源。因此后续就有了一些计算上有所改进的轻量级的self-attention。
5.1 2019: GCNet 通道注意力
#GCNet
#论文名称:《GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond》
#论文地址: https://arxiv.org/abs/1904.11492
#github地址:https://github.com/xvjiarui/GCNet
5.1.1 引言
《GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond》是清华和微软团队提出来的,主要改进是在Non-local基础上,结合SENet的思路,获得不错的效果的同时,大幅降低Non-local的参数量。
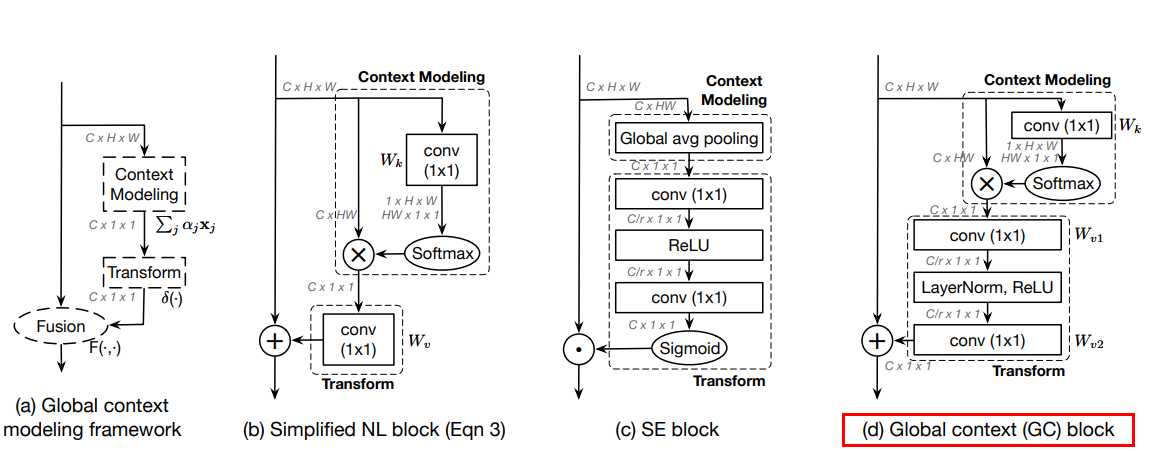 如上图的b, d, b是Nol-local的简单改进版本,虽然参数量下去了,但是效果一般。于是结合SENet的思路,设计了d版本,即最终的GCNet。
如上图的b, d, b是Nol-local的简单改进版本,虽然参数量下去了,但是效果一般。于是结合SENet的思路,设计了d版本,即最终的GCNet。
5.1.2 亮点
- Query和Value向量的生成并没有经过卷积操作,而是特征图的reshape和直接表示。
- GCNet本质上还是一个通道Attention,但是其通道权重的生成是分为两个步骤: a. 如d中的上方的虚线方框所示:对每个通道的特征空间图做空间自注意力,即为该通道的权重;b. 如图d的下方虚线方框所示,对通道权重做类似Transform操作,即各通道信息的进一步交汇和融合。
- 因此可以认为GCNet为 通道注意力 + 半空间注意力。
5.2 2019: CC-Attention
5.2.1 引言
CCNet(Criss Cross Network)的核心是重复十字交叉注意力模块。该模块通过两次CC Attention,可以实现目标特征像素点与特征图中其他所有点之间的相互关系,并用这样的相互关系对目标像素点的特征进行加权,以此获得更加有效的目标特征。
- non-local 模型中, 因为要考虑特征图每个像素点与所有像素点的关系,时间复杂度和空间复杂度为 O(HW*HW)。
- 在CC Attention模块中,计算特征图中每个像素点与其对应的行列的像素点的关系,时间复杂度和空间复杂度O(HW*(H + W - 1)) ,相比前者降低了一个1~2个数量级。
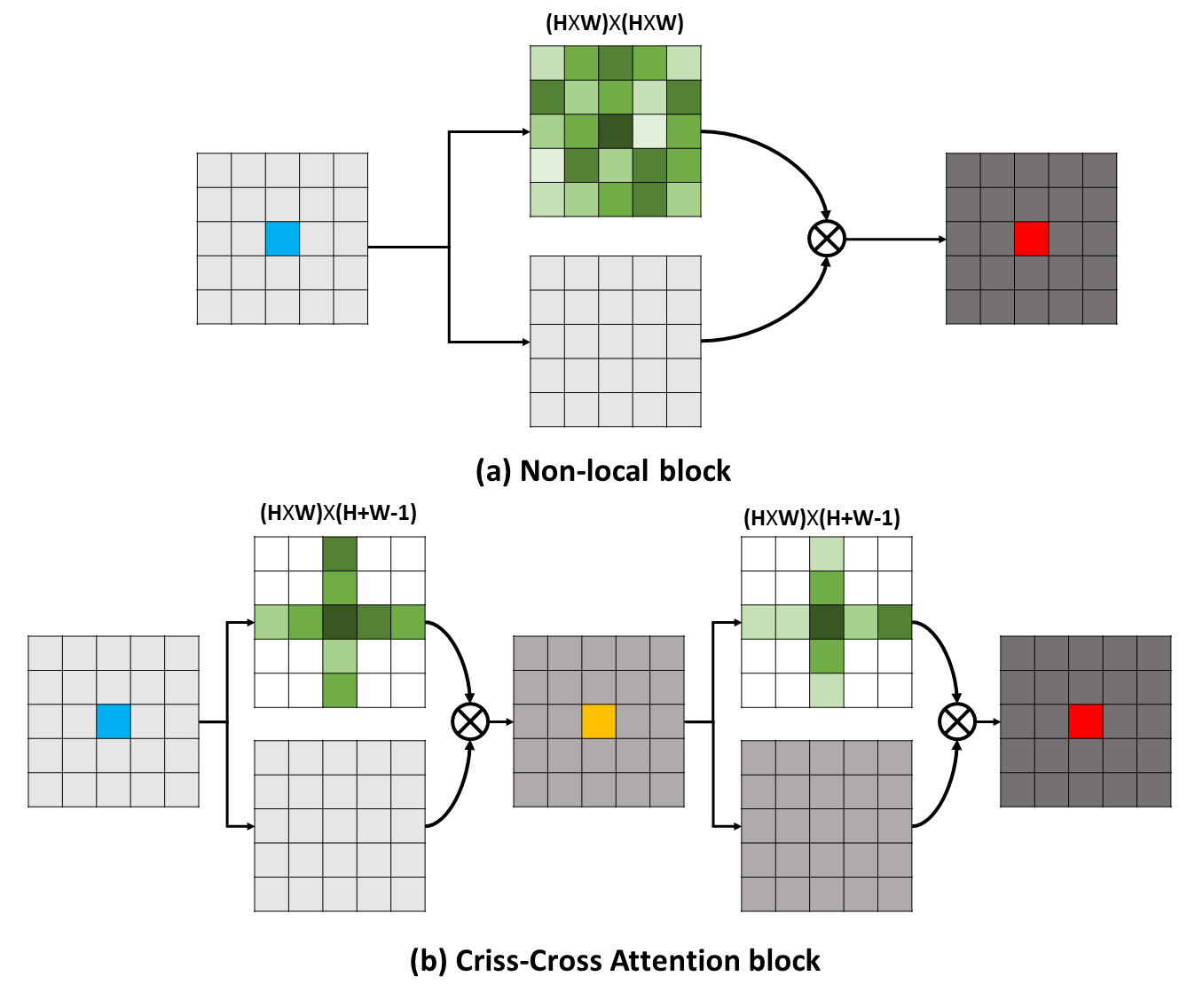
5.2.2 理论实现
还是基于self-attention的思路,使用Q和K向量来确定权重,再与V值取权重和。
X: (batch,c1,h,w) #输入特征图
Q: (batch,c2,h,w) #Query查询向量
K: (batch,c1,h,w) #Key 键值向量
V: (batch,c1,h,w) #Value 值向量
获取权重A
暂先不考虑Batch
- step1: 取Q中特征图中某一像素点的所有通道值:q = Q(i,j) , size = (1, c2)
- step2: 取K特征图中与q同一行和同一列的所有像素点的所有通道值, 交叉位置取了两次,但只选一次. k的 size = (c2, h+w - 1)
- step3: q*k, 得到q_atten, size = (1, h+w - 1), 并对这(h + w -1) 个值进行softmax操作,即权重和为1.
- step4: 对Q中的所有像素点重复step2 和 step3, 即得到了每个像素点的归一权重。此时atten.size = (batch, h,w, h + w - 1)
Affinity操作
上面已经获取了Atten — (batch, h, w, h + w - 1)。接下来将权重施加在V上。 先不考虑batch
- step1: 获取Atten中某个像素点的所有权重, A = Atten(i,j) , size = (1, h + w -1)
- step2: 取V的某一通道Cn 的特征图Vn, size = (h, w) , 选取Vn上与A对应位置的同一行和同一列的数值,记作vn,size = (1, h + w - 1)
- step3: vn 与 A.T 相乘,即得到加权后的vn值,size = (1,1)
- step4: 对V中的所有通道重复step2 和 step3操作。
- step5: 对Atten中的所有像素点重复上述4步操作。
- step6: 残差网络:H‘ = CCAtten(H) + H
全部信息获取
一个CCAttention,只能获取当前位置上同一行和一列的信息,如果叠加两个CCAttention,就可以获取全局信息。
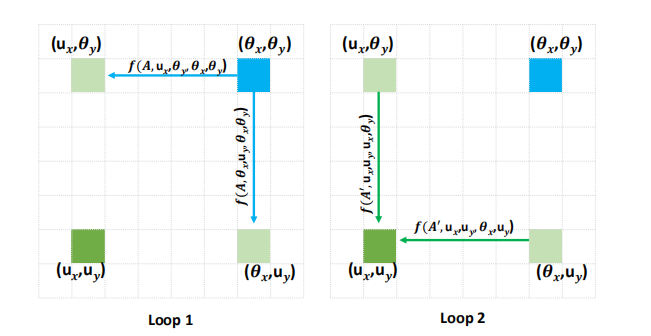
- 如目标像素点是(Ux,Uy) ,想要获取(θx, θy)的关系。
loop1: 像素点(Ux, θy)和 (θx, Uy)通过一次CCAtten 可以建立与(θx, θy)的关系;
loop2: 像素点是(Ux,Uy) 通过CCAtten可以获取与 像素点(Ux, θy)和 (θx, Uy)的联系,从而间接取得与(θx, θy)的联系。
即通过两次CCAtten , 可以建立目前像素点与任意像素点的信息融合。
5.2.3 代码实现
5.2.3.1 官方实现
虽然上面给出了对CCAttention 的理论逻辑的理解,但如果按照该逻辑使用循环进行代码设计,很占计算资源,计算速度也会很慢,而且反向传播也不易做到。我有查看网上的一些实现(包括官方源码),似乎需要自定义的cuda算子,这个扩展性并不友好。
https://github.com/speedinghzl/CCNet
 需要注意的是: 这里的self-attention, 主要是空间注意力,并没有涉及通道注意力。
纯pytorch也是可以实现的。见参考链接;
需要注意的是: 这里的self-attention, 主要是空间注意力,并没有涉及通道注意力。
纯pytorch也是可以实现的。见参考链接;
5.3 2020: MetNet-Axial Attention
#MetNet论文地址:https://arxiv.org/pdf/2003.12140.pdf
#Axial-Attention论文地址:https://arxiv.org/abs/1912.12180
5.3.1 引言
Axial Attention,即轴向注意力。之前关注到Axial Attention,是在谷歌的天气预报模型MetNet中有使用到。
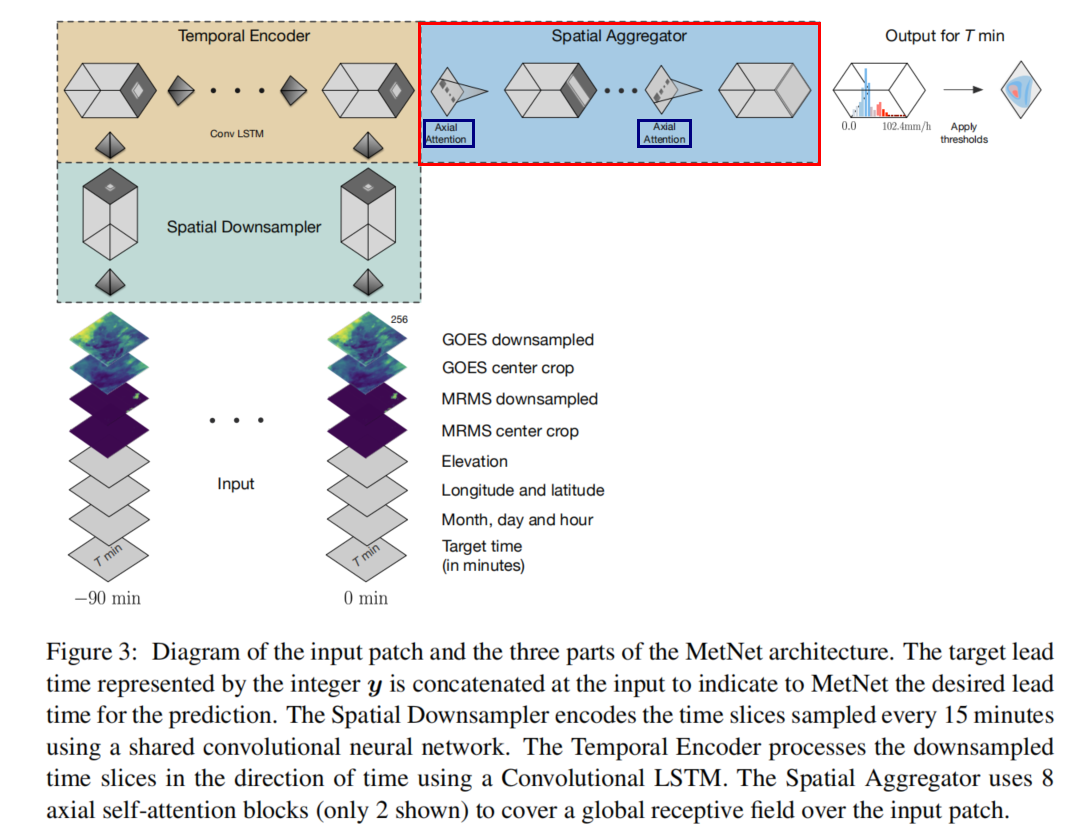
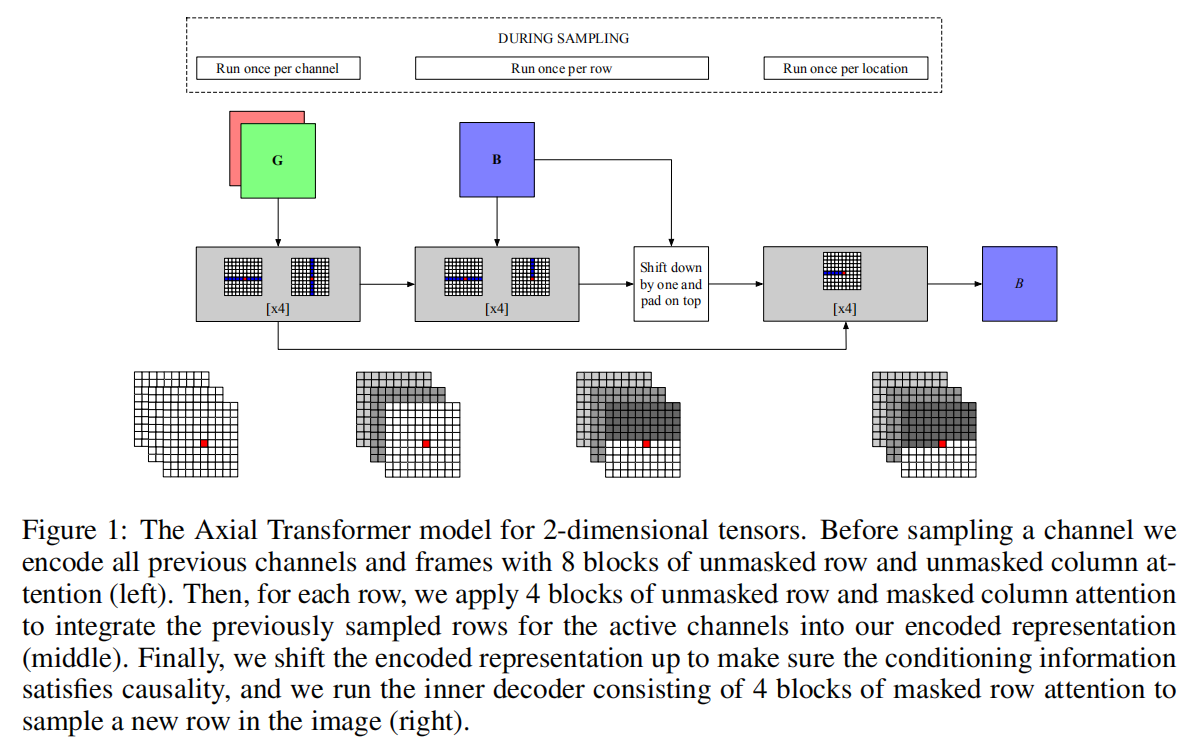 5.3.2 理论实现
5.3.2 理论实现
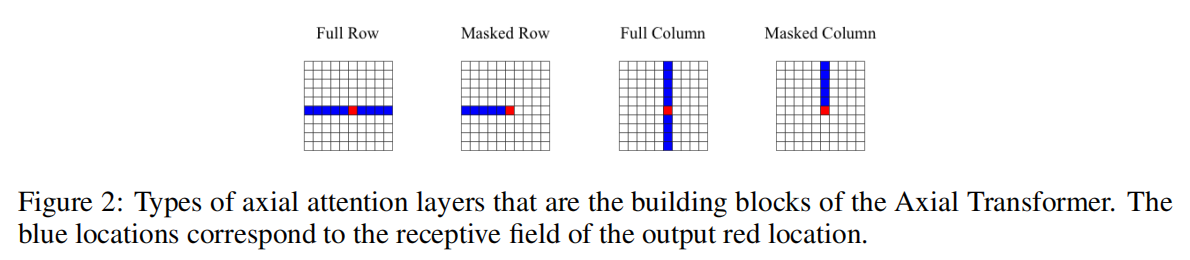 单纯的Axial Attention来看,其实有点类似之前的CC-Attention。
单纯的Axial Attention来看,其实有点类似之前的CC-Attention。
- CC-Attention 的感受野是与目标像素的同一行和同一列的(H + W - 1)个像素
- Axial Attention 的感受野是目标像素的同一行(或者同一列) 的W(或H)个像素
具体的思路也还是self-attention。理论实现方法与CC-Attention大同小异,这里就不赘述了。
5.3.4 总结
单独使用Row Atten(或者Col Attention),即使是堆叠好几次,也是无法融合全局信息的。一般来说,Row Attention 和 Col Attention要组合起来使用才能更好的融合全局信息。
建议方式:
- 方法1:out = RowAtten(x) + ColAtten(x)
- 方法2:x1 = RowAtten(x), out = ColAtten(x1)
- 方法3:x1 = ColAtten(x), out = RowAtten(x1)
这样的一次 out 类似于 一次CCAtten(x) 操作 。
所以一般至少需要迭代两次上述的任意方法,才能融合到全局信息。
5.3.5 开源的Axial Attention
github上有人开源了Axial Attention, 灵活度很高,直接安装使用即可。
- 适用图片
- 适用视频
- 适用通道注意力
- 使用了多头注意力
- 使用了Transformer结构
https://github.com/fangzuliang/axial-attention
pip install axial_attention #安装
6 总结
6.1 表
| Attention | 时间 | 类型 | 权重计算 | 复杂度 | 作者 |
|---|---|---|---|---|---|
SENet |
2017 |
通道注意力 |
池化 + 全连接 + Sigmoid |
O(CC ) |
Jie Hu |
CBAM |
2018 |
通道 + 空间注意力 |
池化 + 全连接/卷积 + Sigmoid |
O(CC * k) |
Sanghyun Woo |
SKENet |
2019 |
通道注意力 |
Inception卷积 + 池化 + 全连接 + softmax |
O(CC) |
Xiang Li |
ECANnet |
2020 |
通道注意力 |
池化 + 通道一维卷积 + Sigmoid |
O(CC) |
Qilong Wang |
RecoNet |
2020 |
通道 + 双空间注意力 |
池化 + 卷积 + Sigmoid |
O((HH + WW + CC) * k*r ) |
Li Wang |
Non-local |
2018 |
自注意力:空间注意力 |
卷积 + 自相关(Q, K) |
O(HW * HW) |
Xiaolong Wang |
DANet |
2019 |
自注意力:通道 + 空间注意力 |
卷积/Reshape + 自相关(Q, K) |
O(HW * (HW + C) |
Jun Fu |
GCNet |
2019 |
自注意力:通道注意力 |
卷积/Reshape + 卷积 + sigmoid |
O(CC) |
YUE CAO |
CCNet |
2019 |
自注意力:空间交叉注意力 |
卷积 + 自相关(Q, K) |
O(HW*(H + W - 1)) |
Zilong Huang |
Axial Attention |
2019 |
自注意力:单轴注意力 |
卷积 + 自相关(Q, K) |
O(HW*H) |
Jonathan Ho |
6.2 对比与启发
回看Attention的设计思路和应用场景,自然而然提出如下问题:
6.2.1 问题
问题1:传统Attenion VS self_attention ?
self-attention的和传统Attention的区别在于特征图权重的获取方式差异,前者是对通过对特征图X做两次映射得到Q,K,之后对Q,K做自相关得到权重,后者一般不是自相关,而是对特征图进行全局池化 + 卷积(or FCN)得到权重。由此前者得到的全局信息更加具体,但计算量往往更大。在像素级别的任务上, self-attention表现应该更好。
问题2:Spatial-Attention & Channel-Attention?
前者的计算量要大于后者,一般情况下,两者搭配起来使用更加合适。搭配方式也可以分为串联(DANet)和并联(CBAM)两种。
问题3:Attention的设计有哪些范式和改进空间?
- 目前传统Attention设计思路为:特征图权重的来源能否更加丰富?
- 将卷积代替FCN, 如SKENet --> ECANet
- 重复多次Attention过程:如SKENet 和 RecoNet
- 单空间注意力 ---> 双空间注意力 ,RecoNet
- 空间自相关 计算 通道注意力 ,如GCNet
- self-attention设计思路为:怎么在不降低精度的基础上降低计算量?
- 通过多步低阶Attention的串行或者并行 实现全局信息的抽取,如CCNet 和 Axial Attention。
6.2.1 启发
可以采取RecoNet的思路:即将 (H, W)都按照通道注意力的方式去实现空间注意力。 可以考虑将(C, H, W)都分别使用Axial Attention的方式进行组合使用。
或者反其道而行:将(C, H, W)两两组合,按照传统或者自注意力(包括CCNet)中实现空间注意力的方式来分别获取(C, H) ,(C, W)这个面上的权重。再进行串联或者并联组合。
self-attention自注意力权重的获取是通过Q、K之间的自相关,有没有可能有更轻便的自相关获取的方式呢?
目前的以RNN为基础的视频预测模型越来越复杂,易收敛性变差,复现难度偏高,由于RNN不能并行计算,需要占用的计算资源也越来越多。RNN的本质是存储记忆和传递时序信息,表现在实现方式上是信息的逐步有序的连接。得其神而不困于形,前人有许多用CNN代替RNN的试验(如TCN: Temporal Convolutional Network、Transformer)并都取得了不错的成绩,因此没有理由不相信信息聚合能力更强的Attention机制能取得更好的结果,佳格的宋宽博士已经用SE-ResUNet做了很好的尝试,也有不错的反馈。
如无必要,勿增实体,尽量用简单的模型做精细的工作,所以勇敢拥抱Attention吧!
7 参考链接
[1]SENet: 《Squeeze-and-Excitation Networks》
[2]CBAM: 《Convolutional Block Attention Module》
[3]SKENet: 《Selective Kernel Networks》
[4]ECANet: 《ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks》
[5]RecoNet: 《Tensor Low-Rank Reconstruction for Semantic Segmentation》
[6]Non-local: 《Non-local Neural Networks》
[7]DANet: 《Dual Attention Network for Scene Segmentation》
[8] GCNet: 《GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond》
[9]CCNet: 《CCNetCriss-CrossAttentionforSemantic_Segmentation》
[10]Axial Attention: 《Axial Attention in Multidimensional Transformers》
[11] MetNet: 《MetNet: A Neural Weather Model for Precipitation Forecasting》
[12] 上述CV attention pytorch版本实现 https://github.com/fangzuliang/MeteorologyFZL/tree/master/CVAttention