1、前言
2019年可以说是语言模型快速发展的一年,BERT、XLNET、Albert等等模型不断刷新各个NLP榜单。在NLP榜单中比较引人注目的应该属于阅读理解型的任务,例如SQuAD等等。以SQuAD为例,模型需要阅读一段给定的文本,然后回答几个问题,问题如果存在答案,答案一定可以在文章中找到。所以说虽然叫阅读理解,但其实和序列标注有点相像,是在给定序列中标出答案段。而这篇论文针对的问题叫开放领域问答(Open-domain QA),对于一个问题Q,模型需要从包含大量文档的知识库中找到答案,而不是像SQuAD数据集一样从一篇文章中寻找。
大部分的语言模型都采用一种称为masked language model,简称MLM的任务来训练,让模型学会类似完形填空一样的能力。通过在大规模语料上的训练,预训练语言模型如BERT实际上已经隐含了一些知识。例如输入一句“The {} is the currency of the United Kingdom”,BERT很有可能会填入单词"pound"。虽然他还是根据词的共现信息学习和推理的,但看上去就像具有所谓的知识一样。从去年开始就有越来越多的研究从单纯语言模型转换为带有知识嵌入的语言模型,例如清华和百度提出的两个同名模型ERNIE。
但上面说的这种隐含知识不好把握,也难以扩展。这篇论文则提出了一种更加模块化且可解释性更强的知识嵌入方法。总的来说,他的方法是训练一个独立的“语境知识抽取器”(contextual knowledge retriever),通过这个抽取器来决定应该在推理时使用哪些知识。而且这个抽取器和语言模型一起进行非监督预训练大大提高模型性能。
2、文章创新之处
- 预训练时masked词 ---- 实体识别模型(BERT-based tagger trained on CoNLL-2003 data)抽取的实体
- 预训练时引入外部知识库(2018年英语维基百科)
- 预训练时增加contextual knowledge retriever,并计算梯度
- 结合快速检索知识库方法----内积向量检索(MIPS, Maximum Inner Product Search,基于LSH哈希算法论文,LSH哈希算法原理)
- contextual knowledge retriever的索引更新和encoder可同时进行 -- 新的加速训练思路
3、方法
3.1 预训练
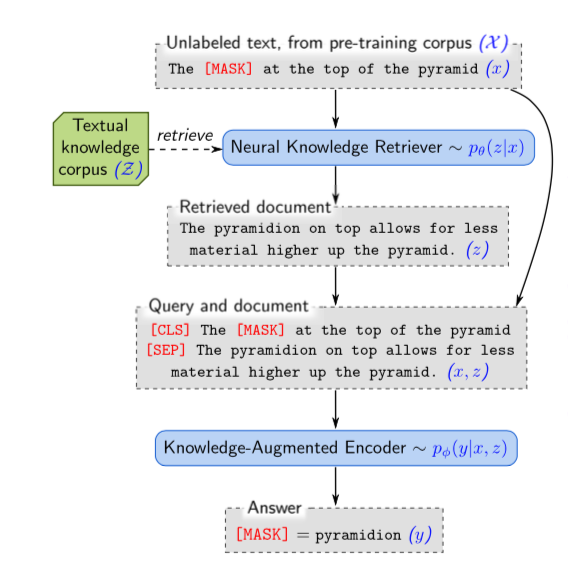
联合概率:由两部分组成①已知输入x,检索的文档z的概率;②获得z之后,基于x,z预测masked词的概率。
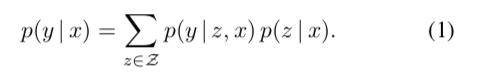
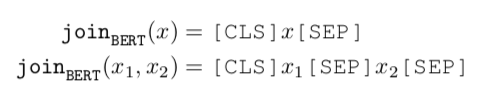
 BERTCLS(joinBERT(x))表示输入bert后句子x的CLS向量
BERTCLS(joinBERT(x))表示输入bert后句子x的CLS向量
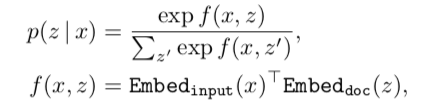 基于p(y|x),文章取得是logp(y|x) 求梯度的。因此有:
基于p(y|x),文章取得是logp(y|x) 求梯度的。因此有:
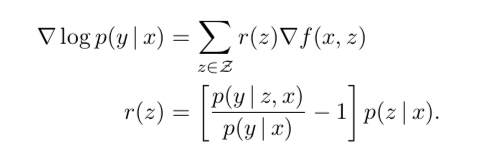 以上公式什么意思呢?就是说当p(y|z,x) > p(y|x)时(说明z对y有贡献),r(z)的前半部分为正,所以p(z|x)越大越好,即该z是对答案有贡献的;当p(y|z,x) < p(y|x)时(说明z对y有误导),,r(z)的前半部分为负,所以p(z|x)越小越好,即该z是对答案不利的。说明基于该公式进行优化,是完全可以收敛的。
以上公式什么意思呢?就是说当p(y|z,x) > p(y|x)时(说明z对y有贡献),r(z)的前半部分为正,所以p(z|x)越大越好,即该z是对答案有贡献的;当p(y|z,x) < p(y|x)时(说明z对y有误导),,r(z)的前半部分为负,所以p(z|x)越小越好,即该z是对答案不利的。说明基于该公式进行优化,是完全可以收敛的。
有人可能要问,公式(1)两边求log并不是右边那样啊。是的,下面请看推到过程:
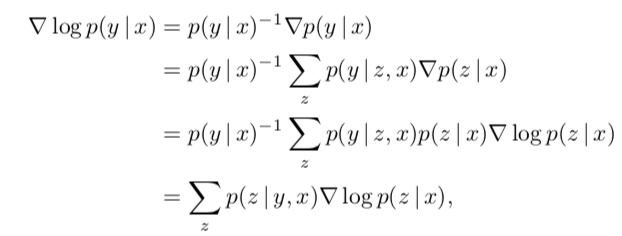 公式说明:第二行->第三行:∇p(z|x) = p(z | x)∇ log p(z | x)
第三行 -> 第四行 贝叶斯公式转换即可
公式说明:第二行->第三行:∇p(z|x) = p(z | x)∇ log p(z | x)
第三行 -> 第四行 贝叶斯公式转换即可
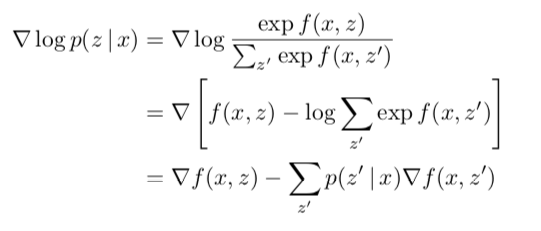 公式说明:第二行 -> 第三行: 其实就是正常的log求导,只不过换了个z'而已
公式说明:第二行 -> 第三行: 其实就是正常的log求导,只不过换了个z'而已
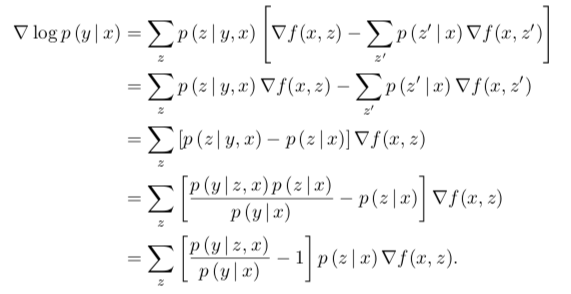 公式说明:第二行 -> 第三行: z'指的是知识库的某一篇文档,z也是,都转化为z即可
公式说明:第二行 -> 第三行: z'指的是知识库的某一篇文档,z也是,都转化为z即可
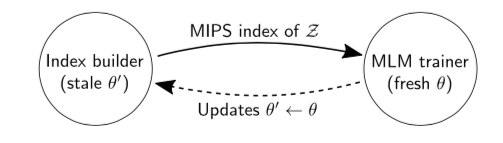
训练策略 a、mask策略:选择实体进行mask b、参数更新策略:mlm的参数每步都更新,但是,由于知识库很大,采用的是索引链接,如果涉及知识抽取器的参数每步都更新的话,将会非常慢,因此,对于知识抽取的参数,每步会记录梯度,但不更新,每隔500steps才更新一次。 下图为index更新流程:即每隔500步,mlm训练器会告诉index builder该更新index了,并把更新好的参数传递
 -额外策略(让训练更好的策略)
a、在研究过程中作者发现了一些能让模型更好训练的策略。
-额外策略(让训练更好的策略)
a、在研究过程中作者发现了一些能让模型更好训练的策略。
b、只训练真正需要知识的词(通常是实体和日期)来训练MLM
c、在topk文档外添加一个虚拟的null document
d、避免让x出现在z中(因为x被mask过,如果它来源于z,那答案就暴露了!)
e、避免冷启动的retriever太渣导致的恶性循环,他们用了一个以ICT作为任务的模型来初始化retriever以下为训练过程各部分的影响对比:

3.2 fine-tuned
利用以上预训练模型进行fine-tuned也很简单,可以选择更新或不更新知识抽取器的参数,实验表明,不更新也能取得较好的效果,但更新的效果肯定更好。
极大似然概率:MLP表示全连接层,h{start}和h{end}分别表示始末位置的token隐层状态。

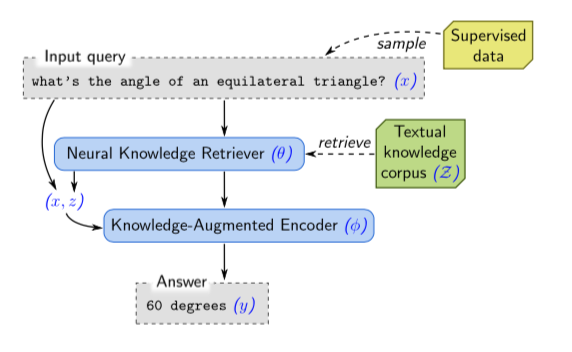
4、结论
在Natural Questions-Open(NQ)、Web Questions(WQ)和Curated Trec(CT)三个数据集上的结果如下“
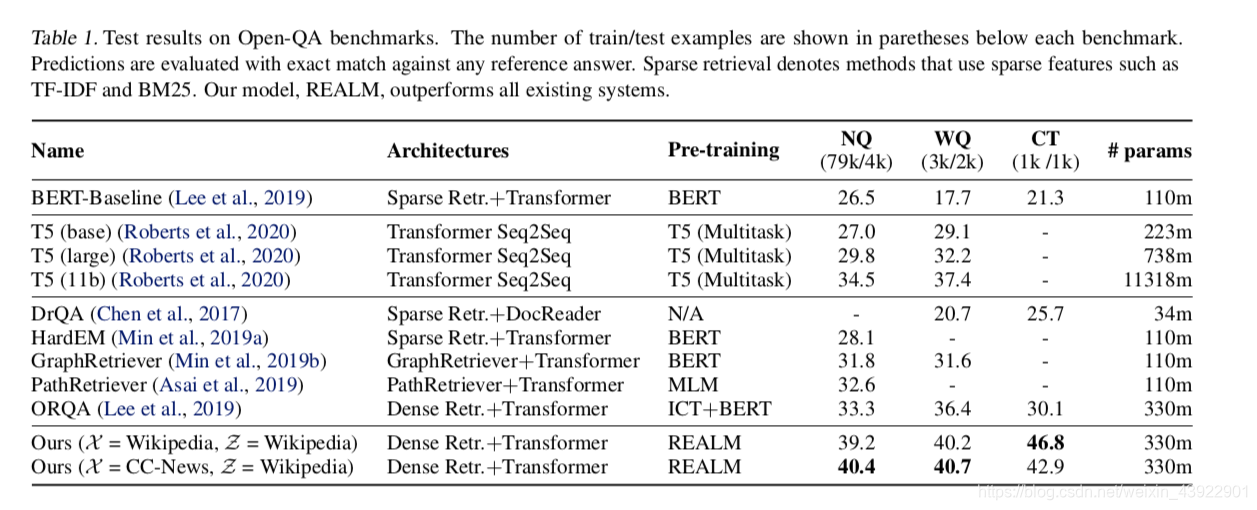 总之一句话,非常牛逼!而且这里模型只取了top 5文档,其他模型可能取了20-80篇,还是打不过他。注意到ours的括号内有两个数据,Z是知识库,很好理解,X是指预训练用的语料。而且通过文章的Ablation Analysis部分可以知道预训练其实是非常关键的一个步骤,对performance的贡献非常大。
总之一句话,非常牛逼!而且这里模型只取了top 5文档,其他模型可能取了20-80篇,还是打不过他。注意到ours的括号内有两个数据,Z是知识库,很好理解,X是指预训练用的语料。而且通过文章的Ablation Analysis部分可以知道预训练其实是非常关键的一个步骤,对performance的贡献非常大。