1、摘要
随着NLP技术的发展,越来越多的新的预训练架构不断刷榜,包括自回归模型(例如GPT)、自动编码模型(例如 BERT)和编码器-解码器模型(例如 T5)。自然语言处理任务在本质可以分为分类、无条件生成和条件生成。但是,目前没有一个预训练框架能够很好地完成所有任务。而在本文中,提出了一种通用语言模型(General Language Model,GLM)来解决这个问题。GLM模型结构有三个主要优点: (1)用一个模型就能在它分类、无条件生成和条件生成任务上表现良好; (2)改进了预训练-微调一致性,在分类上优于类 bert 模型; (3)可以很好地处理可变长度生成。最后,GLM使用了1.25倍BertLarge参数就在GLU的生成任务上取得softa。
2、创新点
- 将单双向注意力同时引入模型
- 下游finetune和预训练保持完全一致性
- 预训练引入变长mask
3、GLM
框架
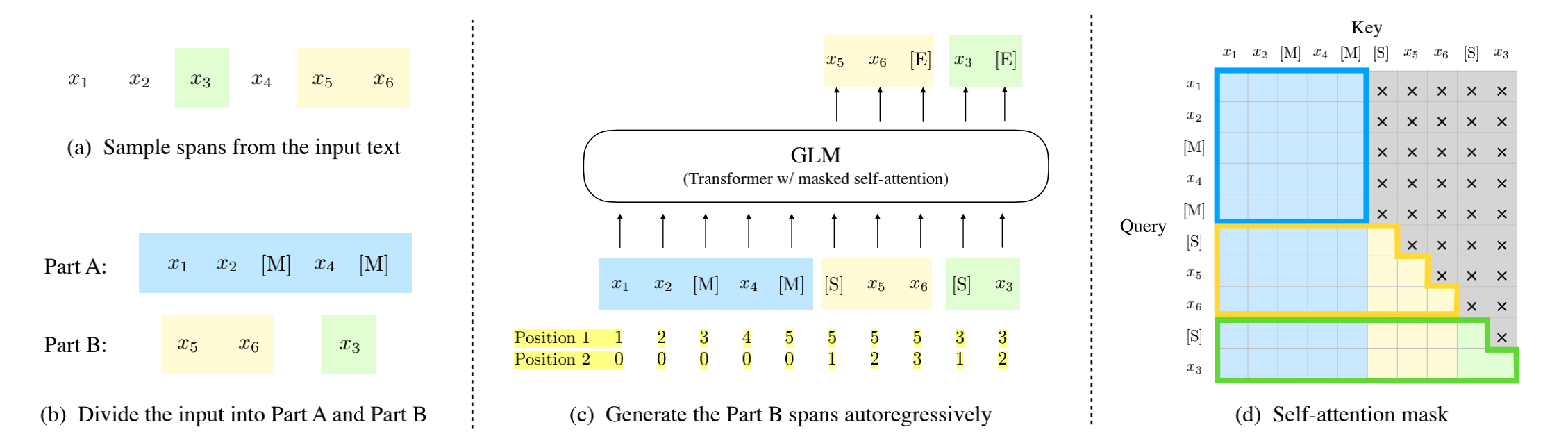
如下图b所示,在GLM模型中,将输入[x1, x2, x3, x4 ,x5, x6]分成了2个部分: Part A:[x1, x2, M, x4, M] ,和Bert的mask输入一样。只是mask可能是一个token,也可能是一个span。 Part B:[x5, x6, x3],注意,Part B并不一定是x3,x5,x6这样按原文顺序来的。论文每个句子采用了随机打乱的策略,然后选择了一种组合。
模型输入:Part A部分开始会添加[CLS],而对于提取的mask部分,会在每个的开始和结束添加一个特殊标记,比如[START], [END]。 位置:Part A -> 0,Part B -> 1 ~ len(Part B) 组合之后的输入格式如下:
句子: [CLS] x1 x2 [M] x4 [M] [S] x5 x6 [S] x3
位置1: 0 1 2 3 4 5 5 5 5 3 3
位置2: 0 0 0 0 0 0 1 2 3 1 2
输出:
x5 x6 [E] x3 [E]
注意力
mask注意力矩阵如上图d所示,从矩阵可以很明显看到,在Part A部分,采用的是自编码注意力,而在Part B部分,采用的是自回归注意力。GLM的注意力就是这样将2部分矩阵进行拼接,形成了即有单向,又有双向的注意力的模型。
模型结构
与BERT相似,主要做了两个修改:
1、改变了归一化和残差的顺序,在largeBERT模型中有效;
2、替换前馈网络为线性网络。
目标函数
1、span mask的长度服从泊松分布(λ=3), 2、span mask部分覆盖50%-100%的原始token,长度使用均匀分布采样。
采样方式与BART一样。重复采样,直到15%的token被mask。
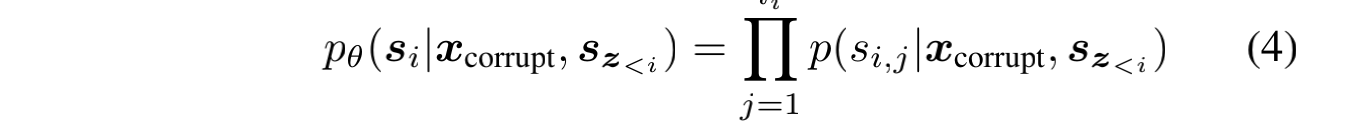
即最大化Part B部分的span生成。
Finetuning GLM
Finetune主要分为分类和生成任务,其具体的流程如下图所示。
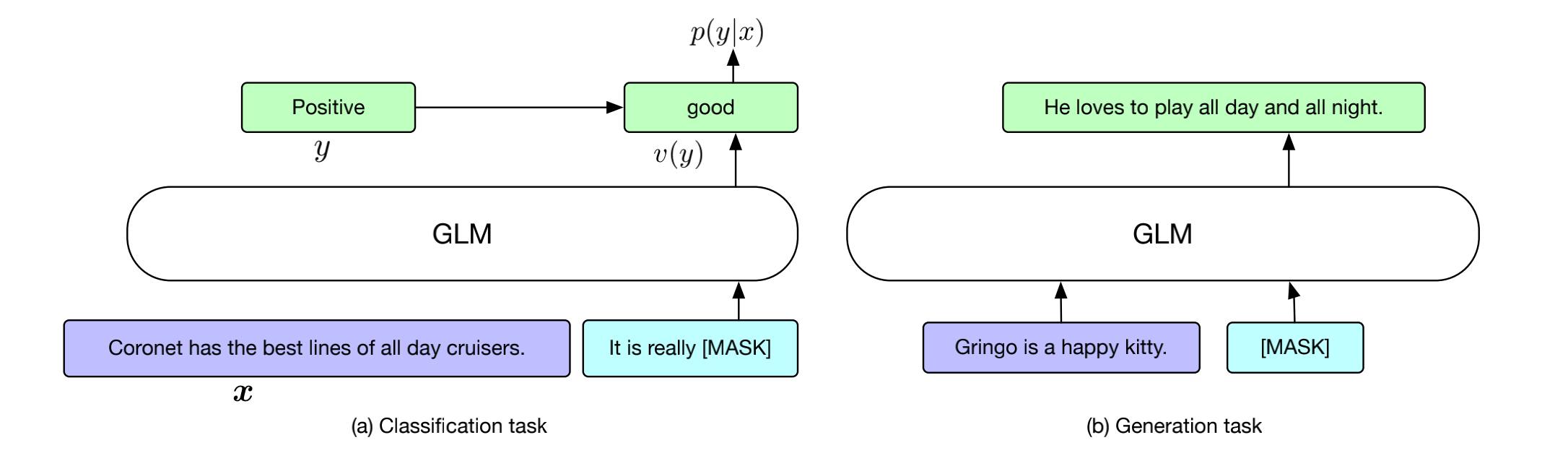 - 分类任务
- 分类任务
将NLU中的分类任务定义为空白填充的生成任务。先将某些标签映射为某个词,比如情感分析积极 -> good,消极 -> bad。然后将映射后的词进行Blank预测。这样一来,就可以这样构造数据:
It’s a beautiful day, I’m in a great mood. *it is [MASK]. [S] good*
I failed in the exam today. I was very depressed. *it is [MASK] [S] bad*
这样,就可以构造最大似然函数如下:
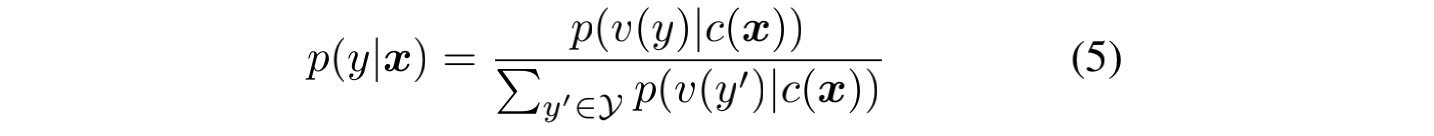 - 生成任务
- 生成任务
只需要将mask添加到输入的句子Part A的结尾即可,然后利用自回归方式生成Part B的token。生成一句结束之后,如果还想继续生成,可把生成之后的句子放入Part A部分,然后同样在Part A结尾处添加mask符。
模型比较
Vs Bert
Bert属于自编码模型。
- 目标任务是预测mask,而且mask之间是相互独立的,因此,Bert不能捕捉到mask之间的相关性;
- Bert只能处理单token的mask,不能处理多个连续的mask token,即只能预测单个token。
Vs XLNet
XLNet属于自回归的模型。 - 需要知道预测token的长度; - 使用双流注意力机制解决了信息泄漏的问题,改变了transfomer的结构,增加了耗时 - XLNet决定一个token是否被独立预测。
Vs T5
- T5也是处理的Blank填充的任务目标,但是GLM使用了单个的transformer编码器学习单向和双向的注意力。
- T5在编码和解码阶段使用不同的位置编码,使用哨兵标记来识别不同的mask跨度,哨兵标记造成了模型能力的浪费和预训练微调的不一致性。而GLM通过共享参数使参数比编码解码模型更有效。
Vs UniLM
XLNet属于自编码的模型。 - UniLM是通过在自编码框架下改变在双向,单向,互相之间的attention mask来统一预训练目标;但还是不能完全捕捉当前token对于前面token的依赖。 - 微调GLM,为了保持和预训练的一致性,其采用mask的方式做生成任务会比自回归更加低效。比如长度上就多了几个token。
结果讨论
- SuperGLUE
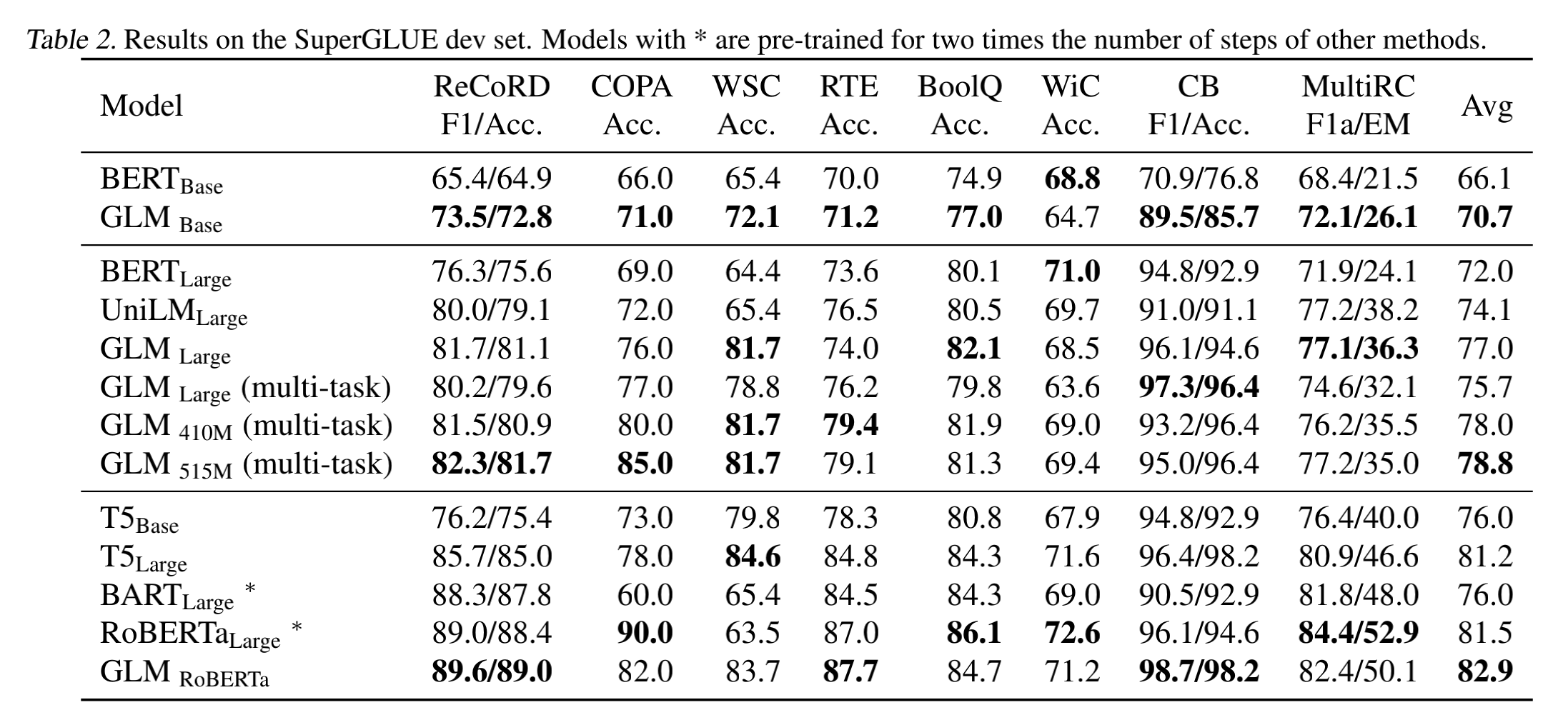
GLMbase/large : 采用和Bert相同的数据和超参数,训练任务也一样,只是预测mask。
GLMbase/large (multi-task) : 在GLMbase/large 的基础上加了变长span,即生成任务
GLMbase/large (multi-task) : 在GLMbase/large (multi-task)的基础上增加了层数,隐层维度和注意力头。 410M (layers=30, hidden=1024, headers=16 ) 和 515M(layers=30, hidden=1152, headers=18 ) ,410M、515M分别是Bert large参数的1.25、1.5倍
GLMRoBERTa:采用和RoBerta large相同的类似数据和超参数,采用GLM训练方式。
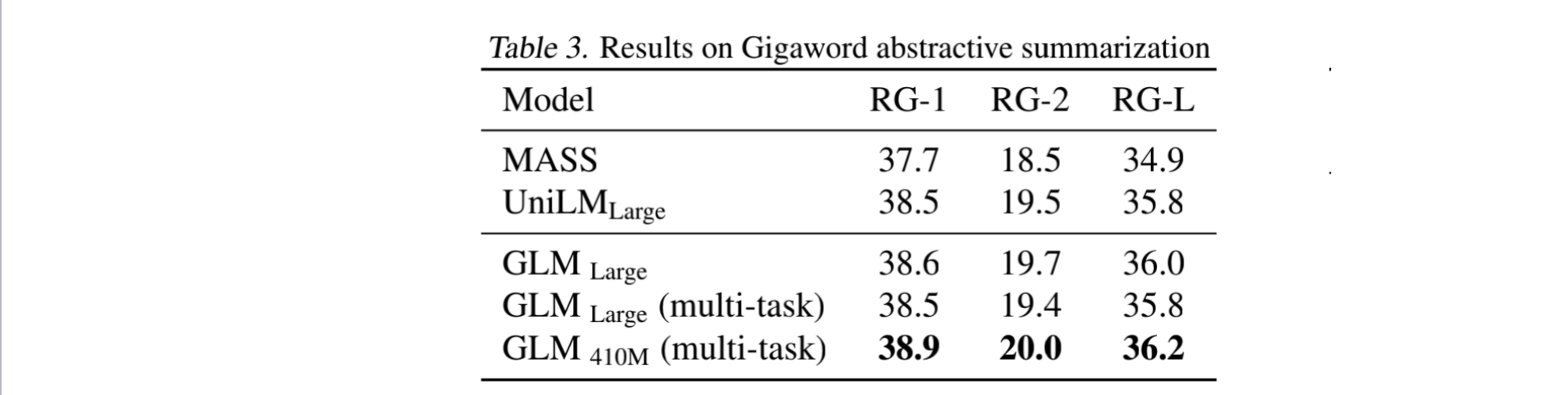
- SEQ2SEQ
- 语言模型
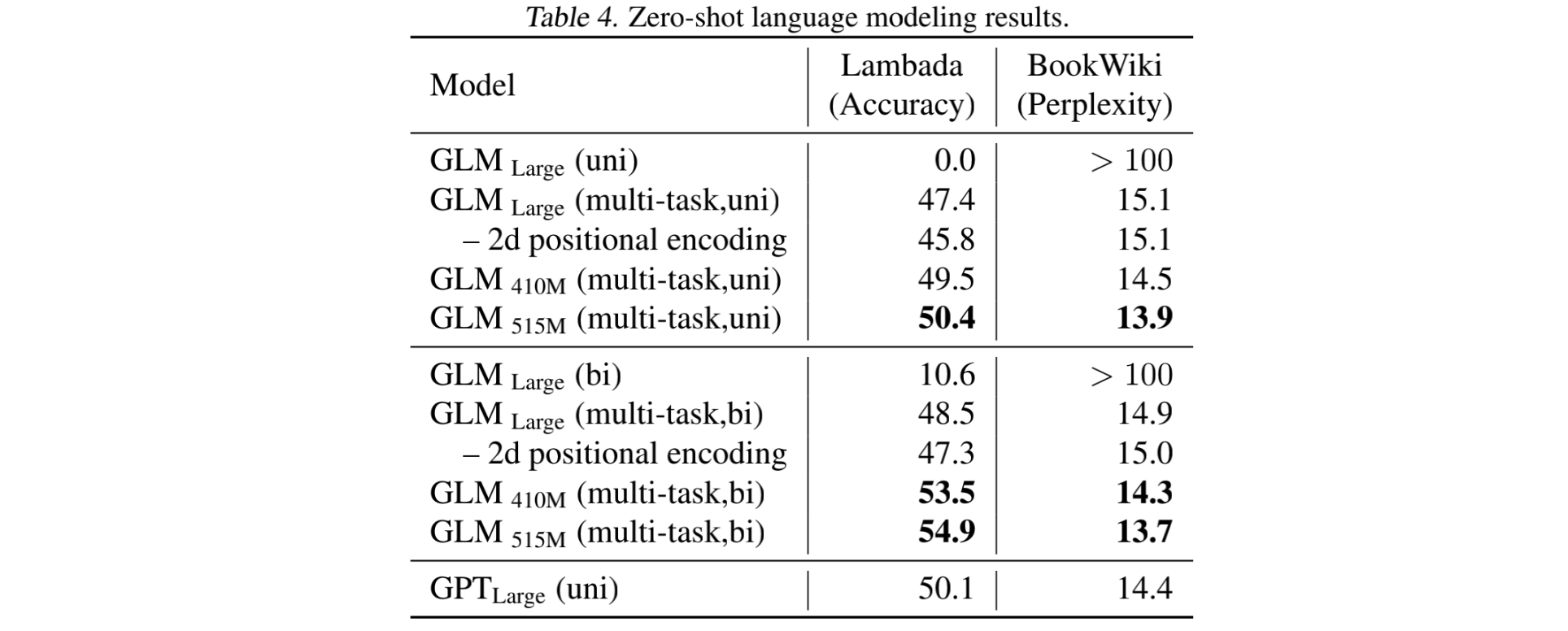
515M的GLM模型相比GPT2 large 在Lambada数据集上的Acc要高,PPL要低。
- 消融实验
之后,本文继续对比了下游任务finetune方式的影响。主要有两种:
1)句子分类的方式。就是直接将句子的输出向量做分类。
2)mask填充方式。就是在输入句子的结尾加上mask,然后采用生成的方式输出分类的词,这种方式和预训练的任务一致。
从表5可以看到,base模型采用cloze方式finetune在NLU的任务上大部分的任务相比classifier有10个点以上的提升。large模型性能损失会相对小一些,但仍没有采用cloze方式的效果好。
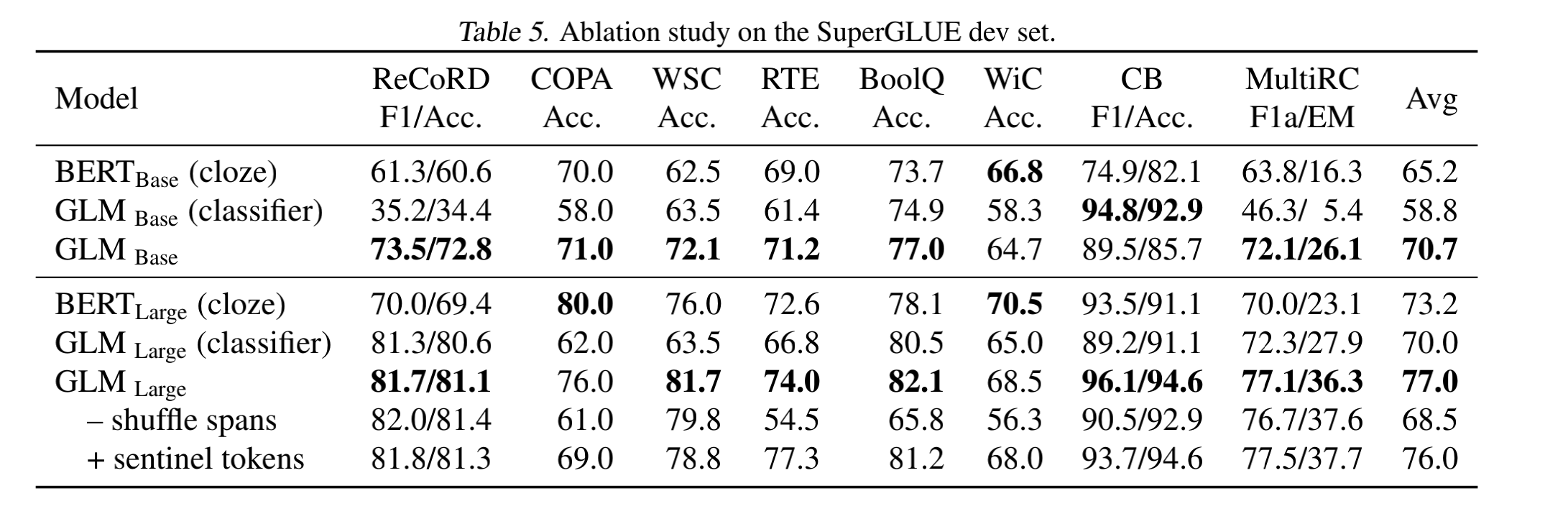 此外,shuffle spans也有一定的提升,sentinel token会降低模型效果,在上面的Table4中可以得出二维的位置表示对模型效果也有一定提升。
sentinel token:指的是在mask位置上用不同的符号表示不同的span
此外,shuffle spans也有一定的提升,sentinel token会降低模型效果,在上面的Table4中可以得出二维的位置表示对模型效果也有一定提升。
sentinel token:指的是在mask位置上用不同的符号表示不同的span
结论
GLM 是一个用于自然语言理解、生成和分类的通用预训练框架。研究表明,自然语言理解任务可以表示为条件生成任务,因此可以用自回归模型处理,GLM 将不同任务的预训练目标统一为自回归Blank填充,采用混合注意掩码和新的2D 位置编码。实验结果表明,对于 NLU 任务,GLM 方法优于以前的方法,能够有效地共享不同任务的参数。希望将 GLM 扩展到更大的Transformer模型和更多的预训练数据,验证其性能。